
Запрос к единственной таблице может использовать несколько индексов
Пересказ статьи Daniel Hutmacher. Querying a single table can use multiple indexes
Может ли SQL Server собрать вместе два различных индекса в запросе к единственной таблице, а не просто взять не вполне оптимальный кластеризованный индекс для сканирования? Короткий ответ - да, в довольно узком диапазоне условий.
Давайте создадим демо-таблицу для экспериментов:
Вот два некластеризованных индекса, с которыми мы хотим поиграть:
Можно увидеть, что пока мы ограничиваемся запросом столбцов B и C, индекс по большей части будет достаточно эффективен. Но если запросить B, C и D, могут использоваться Index1 и Index2, или SQL Server сдастся и вернется к простому сканированию всего кластеризованного индекса?
Я хотел, чтобы этот запрос
генерировал подобный план - соединение индекса Index1 с индексом Index2, использующего столбец C:
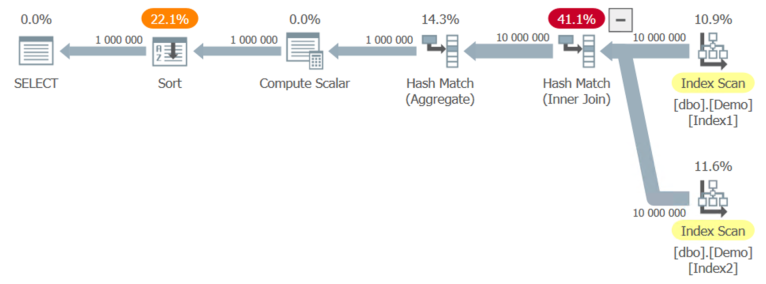
... но заканчивается все этим:

Изменяя запрос несколько раз для включения подмножества строк таблицы, я, наконец, получил план, который хотел:
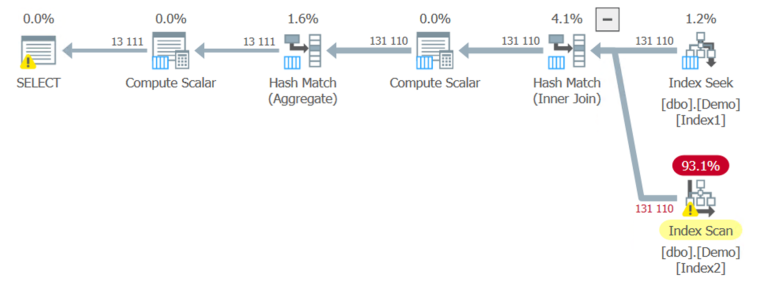
Как и всегда, оптимизация - это игра с порогами. Оптимизатор SQL Server будет испытывать пару различных планов, пока не обнаружит тот, который лучше работает. Количество строк, генерируемых выборкой, скажет какой план наиболее эффективен.
Большинство запросов будут тупо сканировать кластеризованный индекс (Clustered Index Scan).
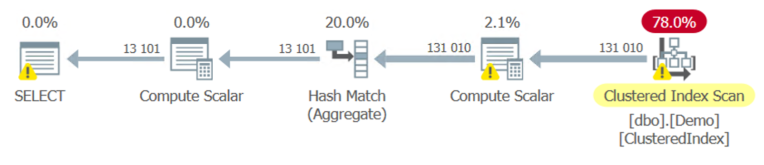
Проверяя немного меньше данных, мы можем получить преимущество от поиска в индексе (Index Seek) Index1 и сканирования индекса (Index Scan) Index2. И пока мы все еще сканируем один из индексов, полный ввод/вывод уменьшается приблизительно на 50%. Но мы вводим оператор Hash Match (Join), который добавляет стоимость CPU. Стоимость этого оператора соединения - это то, что делает данный план эффективным, пока мы имеем дело с относительно небольшим числом строк, но делает его очень дорогим для использования всей таблицы.
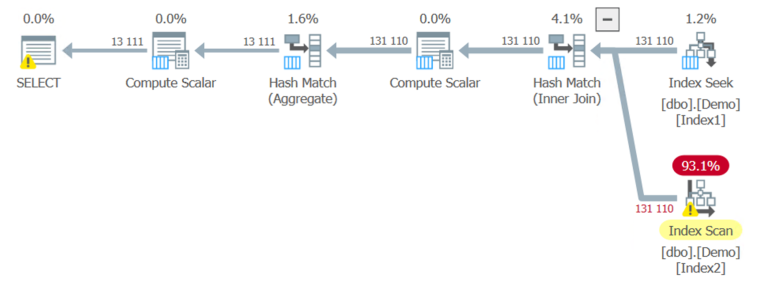
Если использовать сравнительно небольшую выборку строк, SQL Server посчитает, что Key Lookup наиболее эффективен. Идеей этой статьи было посмотреть, сможет ли SQL Server выполнить “Key Lookup” на некластеризованном индексе - в этом случае на Index2, но, похоже, что это не так. Вместо этого мы получаем классический старый Key Lookup на кластеризованном индексе:
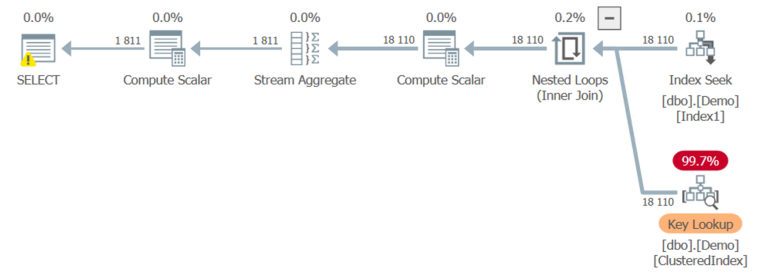
Мне было интересно, возможна ли такая вещь как “Key Lookup” на некластеризованном индексе, но теперь, когда я думаю об этом, то не вижу, какое преимущество это могло бы дать. Однако я был приятно удивлен, что SQL Server будет реально конструировать соединение между двумя индексами на одной и той же таблице, несмотря на то, что абсолютное большинство запросов будет выполнять либо сценарий полного сканирования кластеризованного индекса, либо Key Lookup.
Но изредка вы можете получить выгоду от использования этого шаблона явно выстраивая запрос, который это делает, когда SQL Server не может автоматически выбрать план соединения индексов. Либо потому, что операции ввода-вывода важнее ЦП, либо потому, что вы думаете, что знаете что-то, чего не знает оптимизатор SQL Server.
1. Кучи в SQL Server: часть 3 - некластеризованные индексы
2. Поиск в индексе (Index Seek)
3. Типы индексов SQL Server
4. Об использовании индексов
CREATE TABLE dbo.Demo (
ClusteredKey int NOT NULL,
A int NOT NULL,
B int NOT NULL,
C int NOT NULL,
D int NOT NULL,
CONSTRAINT ClusteredIndex PRIMARY KEY CLUSTERED (ClusteredKey)
);
WITH numbers AS (
SELECT i
FROM (VALUES (0), (1), (2), (3), (4),
(5), (6), (7), (8), (9)) AS n1(i))
--- 10 миллионов строк:
INSERT INTO dbo.Demo (ClusteredKey, A, B, C, D)
SELECT x.i AS ClusteredKey, x.i/100 AS A, x.i/10 AS B, x.i AS C, x.i*10 AS D
FROM (
SELECT n1.i+n2.i*10+n3.i*100+n4.i*1000+n5.i*10000+n6.i*100000+n7.i*1000000 AS i
FROM numbers AS n1, numbers AS n2,
numbers AS n3, numbers AS n4,
numbers AS n5, numbers AS n6,
numbers AS n7
) AS x;Вот два некластеризованных индекса, с которыми мы хотим поиграть:
CREATE INDEX Index1
ON dbo.Demo (B) INCLUDE (C)
WITH (DATA_COMPRESSION=PAGE);
CREATE UNIQUE INDEX Index2
ON dbo.Demo (C) INCLUDE (D)
WITH (DATA_COMPRESSION=PAGE);Можно увидеть, что пока мы ограничиваемся запросом столбцов B и C, индекс по большей части будет достаточно эффективен. Но если запросить B, C и D, могут использоваться Index1 и Index2, или SQL Server сдастся и вернется к простому сканированию всего кластеризованного индекса?
Что я хотел, и что я получил
Я хотел, чтобы этот запрос
SELECT B, AVG(1.0*D)
FROM dbo.Demo
GROUP BY B
ORDER BY B
OPTION (MAXDOP 1);генерировал подобный план - соединение индекса Index1 с индексом Index2, использующего столбец C:
... но заканчивается все этим:
Изменяя запрос несколько раз для включения подмножества строк таблицы, я, наконец, получил план, который хотел:
SELECT B, AVG(1.0*D)
FROM dbo.Demo
WHERE B BETWEEN 100000 AND 113110
GROUP BY B
OPTION (MAXDOP 1);Как и всегда, оптимизация - это игра с порогами. Оптимизатор SQL Server будет испытывать пару различных планов, пока не обнаружит тот, который лучше работает. Количество строк, генерируемых выборкой, скажет какой план наиболее эффективен.
Три диапазона, три исхода
Большинство запросов будут тупо сканировать кластеризованный индекс (Clustered Index Scan).
SELECT B, AVG(1.0*D)
FROM dbo.Demo
WHERE B BETWEEN 100000 AND 113000
GROUP BY B
OPTION (MAXDOP 1)Проверяя немного меньше данных, мы можем получить преимущество от поиска в индексе (Index Seek) Index1 и сканирования индекса (Index Scan) Index2. И пока мы все еще сканируем один из индексов, полный ввод/вывод уменьшается приблизительно на 50%. Но мы вводим оператор Hash Match (Join), который добавляет стоимость CPU. Стоимость этого оператора соединения - это то, что делает данный план эффективным, пока мы имеем дело с относительно небольшим числом строк, но делает его очень дорогим для использования всей таблицы.
SELECT B, AVG(1.0*D)
FROM dbo.Demo
WHERE B BETWEEN 100000 AND 113250
GROUP BY B
OPTION (MAXDOP 1)Если использовать сравнительно небольшую выборку строк, SQL Server посчитает, что Key Lookup наиболее эффективен. Идеей этой статьи было посмотреть, сможет ли SQL Server выполнить “Key Lookup” на некластеризованном индексе - в этом случае на Index2, но, похоже, что это не так. Вместо этого мы получаем классический старый Key Lookup на кластеризованном индексе:
SELECT B, AVG(1.0*D)
FROM dbo.Demo
WHERE B BETWEEN 100000 AND 101000
GROUP BY B
OPTION (MAXDOP 1)Заключение
Мне было интересно, возможна ли такая вещь как “Key Lookup” на некластеризованном индексе, но теперь, когда я думаю об этом, то не вижу, какое преимущество это могло бы дать. Однако я был приятно удивлен, что SQL Server будет реально конструировать соединение между двумя индексами на одной и той же таблице, несмотря на то, что абсолютное большинство запросов будет выполнять либо сценарий полного сканирования кластеризованного индекса, либо Key Lookup.
Но изредка вы можете получить выгоду от использования этого шаблона явно выстраивая запрос, который это делает, когда SQL Server не может автоматически выбрать план соединения индексов. Либо потому, что операции ввода-вывода важнее ЦП, либо потому, что вы думаете, что знаете что-то, чего не знает оптимизатор SQL Server.
SELECT Demo.B, AVG([lookup].D)
FROM dbo.Demo WITH (INDEX=Index1)
INNER JOIN dbo.Demo AS [lookup] WITH (INDEX=Index2) ON Demo.C=[lookup].C
GROUP BY Demo.B
ORDER BY Demo.B
OPTION (MAXDOP 1);Статьи по теме
1. Кучи в SQL Server: часть 3 - некластеризованные индексы
2. Поиск в индексе (Index Seek)
3. Типы индексов SQL Server
4. Об использовании индексов
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой