
Статистика для улучшения производительности: сравнение SQL Server и Oracle
Пересказ статьи Pablo Echeverria. SQL Server vs Oracle Query Statistics to Improve Performance
Не всегда проблемы проявляются в тот момент, когда мы ведем наблюдение. К счастью, каждый движок базы данных содержит представления, которые удерживают прошлые запросы в течение более продолжительного времени. Эти представления могут помочь администратору баз данных вести упреждающий мониторинг кэшированных планов выполнения с целью улучшения существующих запросов и, насколько это возможно, избежать проблем до их возникновения. Но эту информацию необходимо правильно интерпретировать, знать как извлечь и измерить каждое поле, является ли значение накопительным или нет.
В этой статье мы увидим, как определить, какие планы выполнения находятся в кэше и их накопленную статистику, сколько раз они были выполнены, и какое число различных планов выполнения имеется.
Запрос Oracle для получения статистики запросов
Ниже представлен запрос к представлению v$sqlstats, который дает требуемую информацию.
SELECT
SQL_FULLTEXT "Text",
ROWS_PROCESSED "Rows",
EXECUTIONS "Runs",
ROUND(EXECUTIONS/EXTRACT(SECOND FROM SYSTIMESTAMP-TO_TIMESTAMP((SELECT MIN(FIRST_LOAD_TIME) FROM GV$SQL S WHERE S.SQL_ID=ST.SQL_ID), 'YYYY-MM-DD/HH24:MI:SS')), 2) "Calls/Sec",
ROUND(ELAPSED_TIME/1000000,2) "TimeSec",
ROUND(CPU_TIME/1000000,2) "CpuTimeSec",
ROUND(APPLICATION_WAIT_TIME/1000000,2) "WaitTimeSec",
ROUND(CONCURRENCY_WAIT_TIME/1000000,2) "ParallelTimeSec",
ROUND(CLUSTER_WAIT_TIME/1000000,2) "ClusterTimeSec",
ROUND(USER_IO_WAIT_TIME/1000000,2) "IOtimeSec",
ROUND((PHYSICAL_READ_BYTES+PHYSICAL_WRITE_BYTES)/1024/1024/1024,2) "IOinGB",
ROUND(SHARABLE_MEM/1024/1024/1024,2) "SharableMemGB",
ROUND(PARSE_CALLS/DECODE(EXECUTIONS, 0, DECODE(PARSE_CALLS, 0, 1, PARSE_CALLS), EXECUTIONS), 2) "Parses/Executions",
PX_SERVERS_EXECUTIONS "DOP",
LOADS "Loads",
VERSION_COUNT "VersionCount",
SORTS/1000 "SortsK",
DISK_READS/1000 "DiskReadsK",
'SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('''||SQL_ID||''',NULL,''ALL +PEEKED_BINDS''));' "ViewPlan"
FROM GV$SQLSTATS ST
ORDER BY (
SELECT MAX(COLUMN_VALUE)
FROM SYS.ODCINUMBERLIST(
EXECUTIONS/EXTRACT(SECOND FROM SYSTIMESTAMP-TO_TIMESTAMP((SELECT MIN(FIRST_LOAD_TIME) FROM GV$SQL S WHERE S.SQL_ID=ST.SQL_ID), 'YYYY-MM-DD/HH24:MI:SS')),
ELAPSED_TIME/1000000, CPU_TIME/1000000, APPLICATION_WAIT_TIME/1000000, CONCURRENCY_WAIT_TIME/1000000, CLUSTER_WAIT_TIME/1000000,
USER_IO_WAIT_TIME/1000000, (PHYSICAL_READ_BYTES+PHYSICAL_WRITE_BYTES)/1024/1024/1024, SHARABLE_MEM/1024/1024/1024,
PARSE_CALLS/DECODE(EXECUTIONS, 0, DECODE(PARSE_CALLS, 0, 1, PARSE_CALLS), EXECUTIONS),
PX_SERVERS_EXECUTIONS, LOADS, VERSION_COUNT, SORTS/1000, DISK_READS/1000)) DESC;Вот пример вывода:
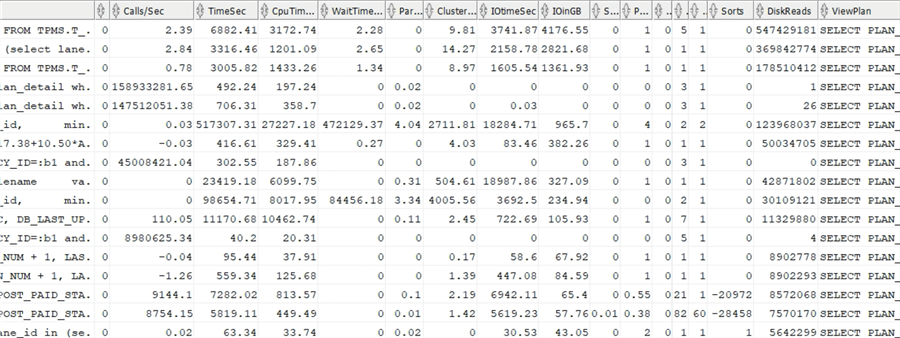
Имеются следующие столбцы:
- Text: Весь оператор, это поле является большим символьным объектом (CLOB).
- Rows: Последнее число строк, которое вернул оператор.
- Runs: Сколько раз был выполнен оператор.
- Calls/Sec: Число выполнений, деленное на время в секундах с момента создания плана.
- TimeSec: Количество времени при последнем выполнении запроса (включая дочерние потоки), не суммируется.
- CpuTimeSec: Количество секунд при последнем выполнении запроса на каждом ЦП (сумма по всем ЦП), не суммируется.
- WaitTimeSec: Количество секунд ожидания приложения при последнем выполнении запроса, не суммируется.
- ParallelTimeSec: Число секунд последней координации с другими потоками, не суммируется.
- ClusterTimeSec: Число секунд последней координации с другими узлами, не суммируется.
- IOtimeSec: Число секунд ожидания ввода/вывода, суммируется.
- IOinGB: Объем ввода/вывода в Гб для записи и чтения вместе, суммируется.
- SharableMemGB: Объем используемой памяти при последнем выполнении плана, не суммируется.
- Parses/Executions: Число раз, когда выполнялся парсинг оператора, деленное на число выполнений. В идеале это значение должно быть меньше единицы (один парсинг на все выполнения), и хуже, когда он выше.
- DOP: Последняя степень параллелизма.
- Loads: Число раз, когда план был загружен в память; высокое значение говорит о высокой нагрузке на память.
- VersionCount: Число планов выполнения для одного и того же оператора; высокие значения указывают на то, что имел место конфликт в кэше библиотеки, и требуются переменные связывания и повторно используемый код (не создается на лету).
- SortsK: Последнее число сортировок, деленное на 1000, не суммируется; высокие значения указывают на интенсивное использование CPU и TEMP, и вам необходимо проверить индексы.
- DiskReadsK: Число чтений, деленное на 1000, суммируется.
- ViewPlan: Оператор для просмотра плана выполнения запроса. С помощью этого SQL_ID вы также можете выполнить SQL Tuning Advisor, чтобы найти способ его улучшения.
Как видно, это представление содержит только три поля с накопительной информацией по всем выполнениям: IOtimeSec, IOinGB и DiskReadsK. Вы можете поделить это значение на число выполнений, чтобы получить среднее значение, или использовать другое представление для получения точного значения на каждое выполнение. Некоторые поля учитывают все выполнения: Runs, Calls/Sec, Parses/Executions, Loads и VersionCount.
Запрос в SQL Server для получения статистики запросов
Представление sys.dm_exec_query_stats предоставляет требуемую информацию, эту информацию требуется агрегировать иначе, чем мы это видели в предыдущем разделе. Запрос представлен ниже, но имейте в виду, что столбцы [max_dop], [max_reserved_threads], [max_used_threads], [max_grant_kb], [max_used_grant_kb] доступны только в SQL Server 2016 и выше:
SELECT
DB_NAME(ISNULL([t].[dbid],
(SELECT CAST([value] AS SMALLINT) FROM [sys].[dm_exec_plan_attributes]([st].[plan_handle]) WHERE [attribute] = 'dbid'))) [DatabaseName],
ISNULL(OBJECT_NAME([t].[objectid], [t].[dbid]),'{AdHocQuery}') [Proc/Func],
MIN(SUBSTRING([t].[text], ([st].[statement_start_offset]/2)+1, ((CASE [st].[statement_end_offset] WHEN -1 THEN DATALENGTH([t].[text]) ELSE [st].[statement_end_offset] END - [st].[statement_start_offset])/2)+1)) [Text],
MAX([st].[max_rows]) [Rows],
SUM([st].[execution_count]) [Runs],
SUM([st].[execution_count])/(SELECT MAX(v) FROM (VALUES (DATEDIFF(ss,MIN([st].[creation_time]),GETDATE())), (1)) AS VALUE(v)) [Calls/Sec],
SUM([st].[max_elapsed_time])/1000000 [TimeSec],
SUM([st].[max_worker_time])/1000000 [CpuTimeSec],
SUM([st].[max_logical_reads]+[st].[max_logical_writes])*8/1024/1024 [IOinGB],
MAX([st].[max_dop]) [DOP],
SUM([st].[max_reserved_threads])-SUM([st].[max_used_threads]) [ThreadsExceeded],
(SUM([st].[max_grant_kb])-SUM([st].[max_used_grant_kb]))/1024 [MemoryExceededMb],
'SELECT [query_plan] FROM [sys].[dm_exec_query_plan](0x'+CONVERT(VARCHAR(MAX),[st].[plan_handle],2)+')' [ViewPlan]
FROM [sys].[dm_exec_query_stats] [st]
CROSS APPLY [sys].[dm_exec_sql_text]([st].[sql_handle]) [t]
GROUP BY [st].[query_hash], [st].[plan_handle], [t].[dbid], [t].[objectid]
ORDER BY (SELECT MAX(v) FROM (VALUES
(SUM([st].[execution_count])/(SELECT MAX(v) FROM (VALUES (DATEDIFF(ss,MIN([st].[creation_time]),GETDATE())), (1)) AS VALUE(v))),
(SUM([st].[max_elapsed_time])/1000000),
(SUM([st].[max_worker_time])/1000000),
(SUM([st].[max_logical_reads]+[st].[max_logical_writes])*8/1024/1024),
(MAX([st].[max_dop])),
(SUM([st].[max_reserved_threads])-SUM([st].[max_used_threads])),
((SUM([st].[max_grant_kb])-SUM([st].[max_used_grant_kb]))/1024)) AS VALUE(v)) DESC;Пример вывода:
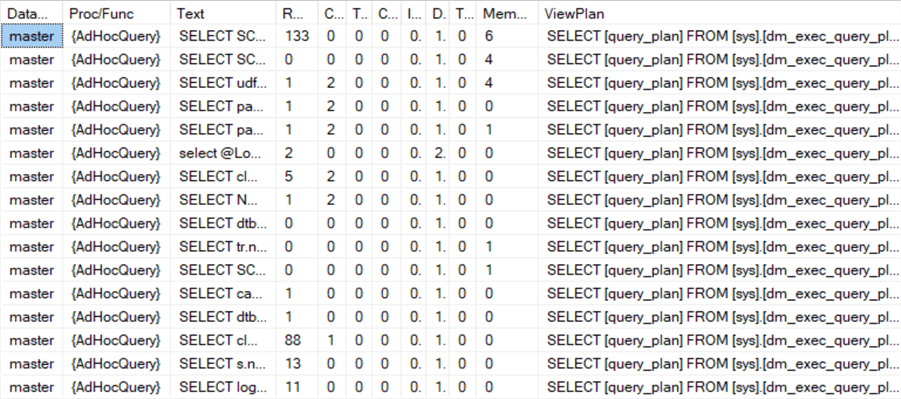
Здесь
- DatabaseName: Имя базы данных, где выполнялся запрос.
- Proc/Func: Имя процедуры или функции, или (ad-hoc запрос), если был послан непосредственно.
- Text: Текст оператора, который был выполнен.
- Rows: Максимальное число строк вывода.
- Runs: Число ваполнений оператора.
- Calls/Sec Число выполнений, деленное на количество секунд с момента времени создания плана (если имеется, иначе 1). Если это значение велико, вы, вероятно, выиграете от улучшения этого запроса, чтобы он выполнялся как можно быстрее с наименьшим количеством ресурсов.
- TimeSec: Число секунд выполнения оператора, суммарно.
- CpuTimeSec: Число секунд использования оператором ЦП, суммарно.
- IOinGB: Величина ввода/вывода в Гб для чтения и записи, суммарно.
- DOP: Максимальная степень параллелизма по всем выполнениям.
- ThreadsExceeded: Разность между зерезервированными и использованными потоками, суммарно. Значение выше 0 указывает на необходимость исследовать план выполнения, поскольку ожидания движка не соответствуют выполненому. Вам нужно сравнить близость предварительного и фактического планов выполнения.
- MemoryExceededMb: Разность между ожидаемым и использованным объемом памяти, суммарно. Значение выше 0 указывает на необходимость исследовать план выполнения, поскольку ожидания движка не соответствуют выполненому. Вам нужно сравнить близость предварительного и фактического планов выполнения.
- ViewPlan: Оператор для просмотра плана выполнения оператора и поиска путей его улучшения.
Замечание. Нам не требуется агрегировать информацию по сессиям и подключениям, поскольку мы хотим получить статистику по всем кэшированным запросам. Как можно увидеть, мы просуммировали информацию по всем выполнениям в столбцах: TimeSec, CpuTimeSec, IOinGB, ThreadsExceeded и MemoryExceededMb. Вы можете поделить это значение на число выполнений для получения среднего значения. Кроме того, некоторые поля предоставляют только максимальные значения по всем выполнениям: Rows и DOP. А некоторые поля учитывают все выполнения: Runs и Calls/Sec.
Заключение
Эти представления имеют более длительный срок хранения и могут помочь вам выявить дорогие запросы, которые выполнялись в прошлом, чтобы найти самые дорогие. Отчет может быть выполнен много раз за день, чтобы выявить то, что может быть улучшено.. В Oracle информация уже сгруппирована, поэтому вы не можете увидеть максимальное или среднее значение, а в SQL Server у вас имеется по одной строке на выполнение, поэтому вы можете группировать информацию так, как пожелаете.
Ссылки по теме
1. Изучение плана запроса в SQL
2. Оптимизация передаваемых непосредственно запросов
3. Как отследить производительность запросов, которые используют хинты RECOMPILE
4. Интеллектуальный анализ кэша планов SQL Server - атрибуты плана
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой