
Пропуски в столбце SQL Identity и пересчет в SQL Server, Oracle и PostgreSQL
Пересказ статьи Andrea Gnemmi. SQL Identity Column Gaps and Conversion in SQL Server, Oracle and PostgreSQL
В первой части этой серии статей мы узнали, что представляет собой столбец identity, а также различные способы его установки и модификации в SQL Server, Oracle и PostgreSQL. Теперь мы глубже заглянем в столбцы identity и рассмотрим такие вопросы, как кэширование значений identity и как преобразовать существующий столбец (содержащий данные) в столбец identity.
Как обычно, в целях тестирования я буду использовать свободно распространяемую базу данных Chinook на Github, которая доступна в форматах различных реляционных СУБД. Это имитация магазина цифровых носителей, содержащей типичные данные. Все, что вам требуется сделать, это загрузить требуемую версию и получить скрипты для создания структур данных и операторов вставки в них данных.
Ранее мы видели, что SQL Server не позволяет определить кэш для столбца Identity (хотя это возможно для последовательностей), но это не означает, что кэша не существует! Фактически даже в SQL Server имеется кэш для повышения производительности, начиная с версии 2012. Значением по умолчанию является 1000 для столбца типа данных INT или 10000 - для BIGINT. Однако это может привести к появлению зазоров в значениях identity в случае несогласованных (неожиданных) выключениях SQL Server, При этом заранее размещенные в кэше значения просто теряются, и столбец identity будет перезапущен с огромным зазором в 1000 значений для типа данных INT!
Давайте продемонстрируем это на следующем примере: мы вставим новую строку в таблицу supplier с помощью оператора INSERT, а затем спровоцируем неожиданное выключение нашего SQL Server:
Проверим значения:

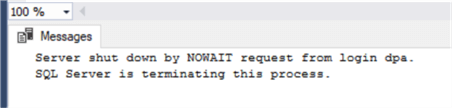
Теперь мы спровоцируем выключение, выполнив следующую команду в новом окне запроса:
Перезапустим службу и проверим значение нашего столбца identity с помощью функции IDENT_CURRENT:
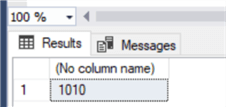
Как и ожидалось, наш столбец identity перепрыгнул на 1000 значений!
Для некоторых таблиц и приложений это может стать проблемой, поэтому хотелось бы знать, что можно сделать, чтобы избежать этого огромного скачка значений?
В SQL Server 2019 и более поздних версиях имеется способ отключить кэш, устанавливая параметр IDENTITY_CACHE ON или OFF. Тем самым мы можем избежать такого возможного зазора в столбцах identity. Давайте попробуем!
Сначала мы можем проверить значение этого параметра с помощью простого запроса в следующем примере:

Теперь мы можем установить этот параметр в OFF:
Давайте снова проверим этот параметр:

А теперь давайте снова попробуем вставить новое значение, а потом спровоцируем неожиданное выключение:

Перезапустим службу и выполним этот запрос снова для проверки.
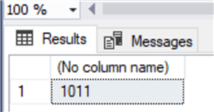
Как видно, мы избежали скачка значений. Чтобы быть точным, скажу, что тот же результат мог быть получен в предыдущих выпусках SQL Server при включении флага трассировки 272 для выключения кэша identity, но побочным эффектом этого флага трассировки является выключение кэша identity на уровне сервера, а не на уровне базы данных, как для параметра IDENTITY_CACHE.
Имейте в виду, что отключение кэша identity может привести к проблемам производительности, особенно если у вас имеется множество вставок в таблицы, имеющих столбцы identity, поэтому установка IDENTITY_CACHE в значение OFF должна быть тщательно протестирована, т.к. это потенциально вредно для производительности INSERT.
Поскольку в Oracle столбец identity непосредственно вытекает из последовательности (Sequences), имеется возможность указать значение кэша. Значение по умолчанию - 20, и также есть возможность указать NOCACHE, что полностью исключает возможность появления больших зазоров в случае неожиданного краха сервера.
Однако в Oracle мы можем получить большие проблемы с производительностью, если не будем использовать кэш в последовательности и столбцах identity, особенно в окружении RAC. Вкратце, RAC - это аббревиатура для Real Application Cluster (реальный кластер приложений), который обеспечивает высокую доступность Oracle; проверенная технология, в которой у нас обычно имеется два узла, на которых работают два экземпляра базы данных Oracle, и если один выходит из строя, другой берет на себя всю нагрузку. Основное отличе от традиционного кластера SQL Server состоит в том, что оба узла активны; тем самым возможна конкуренция, если оба обращаются за одним и тем же объектом, например, к последовательности/столбцу identity. О RAC можно много говорить, как и о способах избежать конкуренции, например, при использовании различных служб для распределения нагрузки, однако это выходит за рамки данной статьи.
Итак, это основа возможных проблем с производительностью при кэшировании. Использование столбца identity или последовательности без кэша надлежащего размера в окружении Oracle RAC может привести к конкуренции в последовательности, к которой обращаются оба узла RAC. Поэтому всегда рекомендуется совместно с разработчиками приложений проверять, сколько вставок в минуту ожидается для таблицы, использующей столбец identity или последовательности. Очевидно, что мы говорим о больших нагрузках OLTP.
Помимо сказанного выше, мы можем также получить проблемы с зазорами в Oracle при неожиданном отключении (например, SHUTDOWN ABORT), когда Oracle ведет себя аналогично SQL Server, что приводит к скачку в идентификаторах, поскольку значения кэша сбрасываются.
Давайте продемонстрируем это. Мы вставим новую строку в таблицу supplier, но сначала мы должны вернуть на 1 INCREMENT BY, который мы изменили в последнем примере части 1, чтобы было легче проверять идентификаторы:
Проверим значения:

Теперь остановим экземпляр Oracle с опцией ABORT для того, чтобы спровоцировать неожиданное выключение. В моем случае это PDB или Pluggable Database, которая является частью CDB или Container Database (более подробно об архитектуре Multitenant вы можете прочитать здесь).
Имейте в виду, что возможно выполнить Shutdown с опцией Abort в PDB только в режиме Archivelog, что эквивалентно режиму восстановления FULL в SQL Server, но режим Archivelog устанавливается на уровне Container (CDB), и потому он устанавливается для всех PDB в контейнере.
Для выключения PDB мы соединяется с хостом посредством SSH, авторизуемся как пользователь Oracle, и входим в контейнер с помощью sqlplus, проверяя сначала, что переменная ORACLE_SID является именем службы нашей базы данных в контейнере:

Теперь мы можем подключиться с помощью sqlplus:
Теперь мы можем отключить базу данных TEST с помощью команды ALTER DATABASE (работает только на PDB) с опцией ABORT. Пожалуйста, делайте это только в среде тестирования!


Теперь снова откроем её:

И мы получим следующую ошибку:

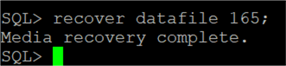
Для восстановления базы данных после неожиданного отключения мы должны восстановить каждый файл данных, используя его номер:
После восстановления каждого из файлов данных мы можем, наконец, открыть переиздание базы данных:


Теперь мы уже можем проверить текущее значение столбца identity, используя тот же трюк из первой части для проверки последовательности Oracle:
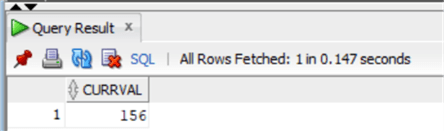
Как видно, мы перепрыгнули на 50 номеров точно в соответствии со значением кэша.
Давайте также выполним пример изменения параметра CACHE, опять таки, это простая операция изменения таблицы:
Таким образом, теперь столбец identity больше не будет использовать кэш, очень просто.
Мы уже видели в первой части, что PostgreSQL использует своеобразный способ обработки кэша для столбцов identity и последовательностей. В нескольких сессиях, в которых вставляются значения в таблицу, каждая использует свой собственный кэш-пул. Это означает, что всякий раз, когда сессия завершается и создается новая, мы получаем зазор, даже без выключения, не важно какого - внезапного или запланированного.
Давайте рассмотрим пример. До вставки новой строки в таблицу supplier мы сначала установим приращение обратно в 1:
Проверим нашу таблицу:
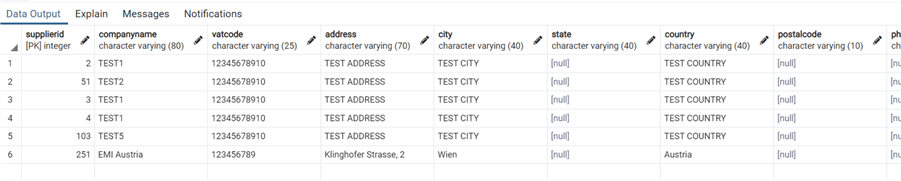
Да, я знаю, что мы еще немного поиграли с данными PostgreSQL ранее, как показано выше!
Теперь мы просто закроем сессию, откроем новую и выполним NEXTVAL подобно тому, как мы это делали в первой части:
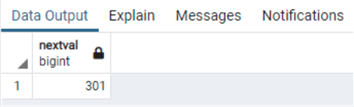
Мы опять прыгнули на 50 значений в кэше. Таким образом, в PostgreSQL зазоры не только возможны, но почти наверняка появятся, и это справедливо как для столбцов identity, так и для последовательностей.
Очень легко добавить столбец identity в существующую таблицу, если мы просто добавляем новый столбец, но что если мы хотим взять существующий столбец и преобразовать его в identity? Это может оказаться непросто в случае, если мы хотим корректно сохранить уже хранящиеся в столбце значения.
В SQL Server нет прямого способа выполнить эту задачу, но есть обходной путь.
Можно создать новую отдельную таблицу со столбцом identity и такой же структуры, как и таблица, столбец которой мы хотим преобразовать. Затем установить IDENTITY_INSERT ON, скопировать все данные из старой таблицы в новую и, наконец, удалить старую таблицу и переименовать новую. Конечно это решение зависит от наличия ссылок Foreign Key на таблицу (вам потребуется удалить ограничения, чтобы удалить старую таблицу).
Итак, пусть мы хотим модифицировать столбец ArtistId в таблице Artist в столбец identity. Поэтому мы сначала создадим новую таблицу Temp_Artist с помощью оператора CREATE TABLE:
Теперь установим IDENTITY_INSERT в значение ON:
А теперь мы может скопировать значения из одной таблицы в другую:
Проверим значеня в новой таблице:
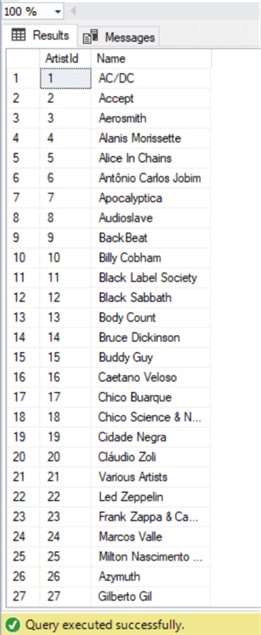
Поскольку все выглядит нормально, мы можем удалить таблицу Artist:

Как ожидалось, мы не можем удалить её, т.к. имеется ссылка Foriegn Key на эту таблицу, поэтому вы должны сначала удалить ограничение. Используя хранимую процедуру SP_FKEYS мы можем проверить, какие ограничения ссылаются на таблицу Artist:

Таким образом, мы можем увидеть, что на столбец ArtistId ссылается ограничение FK_AlbumArtistId, и мы можем удалить его, а потом создать его снова после завершения и переименования новой таблицы:
Теперь мы можем уже удалить старую таблицу:

и переименовать старую, для чего мы будем использовать хранимую процедуру SP_RENAME:
Теперь создадим ограничение внешнего ключа, которое мы удаляли:
Теперь проверим в таблице столбец identity с помощью IDENT_CURRENT:
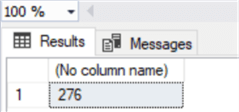
Все сделано, простым обходным путем мы преобразовали существующий столбец в столбец identity, сохранив имеющиеся там значения.
В Oracle мы имеем в точности такое же поведение, как в SQL Server, поэтому для преобразования существующего стролбца в столбец identity мы следуем тем же обходным путем и сначала создаем новую таблицу:
Теперь мы можем выполнить вставку в новую таблицу, поскольку мы установили столбец identity генерированным по умолчанию:
Удалите ограничение на таблице Artist. Чтобы получить ссылки на таблицу в Oracle, вот простой запрос, который использует таблицу DBA_CONSTRAINTS:


Наконец, переименуем нашу новую таблицу и заново создадим ограничение. Для переименования таблицы в Oracle можно использовать оператор ALTER TABLE RENAME:
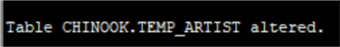
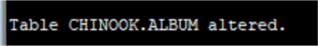
Теперь давайте проверим значение столбца identity:
В Oracle мы видим, что нам необходимо установить столбец identity, чтобы он начинался с последнего имеющегося значения:

Тем самым мы установили наш новый столбец identity!
Для PostgreSQL мы имеем другое решение. Есть возможность непосредственно добавить свойство identity для существующего столбца, сохранив предварительные значения. Давайте выполним те же действия на PostgreSQL, изменив ArtistID в таблице Artist. Посмотрим сначала максимальное значение в столбце:
Теперь мы можем изменить столбец, используя обычное ALTER TABLE ADD и указывая в опции START WITH полученное только что число плюс 1:
Посмотрим теперь на значения в таблице:
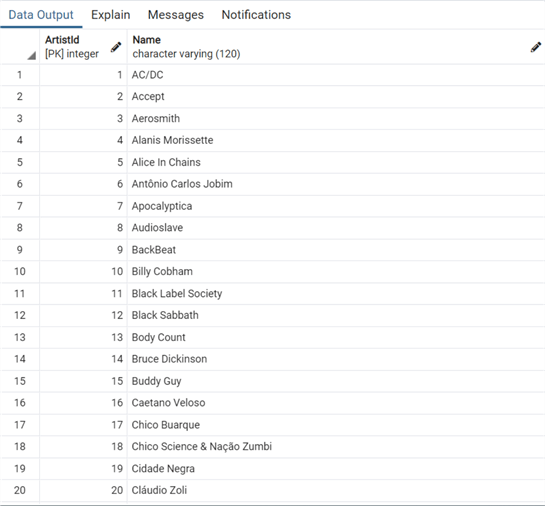
и проверим следующее значение для нашего столбца identity:
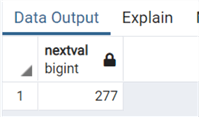
Есть! В PostgreSQL это сделать очень легко и может быть сделано непосредственно без проблем!
Кэш в столбцах SQL Identity
Пример для базы данных SQL Server
Ранее мы видели, что SQL Server не позволяет определить кэш для столбца Identity (хотя это возможно для последовательностей), но это не означает, что кэша не существует! Фактически даже в SQL Server имеется кэш для повышения производительности, начиная с версии 2012. Значением по умолчанию является 1000 для столбца типа данных INT или 10000 - для BIGINT. Однако это может привести к появлению зазоров в значениях identity в случае несогласованных (неожиданных) выключениях SQL Server, При этом заранее размещенные в кэше значения просто теряются, и столбец identity будет перезапущен с огромным зазором в 1000 значений для типа данных INT!
Давайте продемонстрируем это на следующем примере: мы вставим новую строку в таблицу supplier с помощью оператора INSERT, а затем спровоцируем неожиданное выключение нашего SQL Server:
insert into supplier(Companyname, vatcode, address, city, country, email)
values('EMI Austria','123456789','Klinghofer Strasse, 2','Wien','Austria','test@email.com')Проверим значения:
select * from supplierТеперь мы спровоцируем выключение, выполнив следующую команду в новом окне запроса:
SHUTDOWN WITH NOWAIT;Перезапустим службу и проверим значение нашего столбца identity с помощью функции IDENT_CURRENT:
select IDENT_CURRENT('Supplier')Как и ожидалось, наш столбец identity перепрыгнул на 1000 значений!
Для некоторых таблиц и приложений это может стать проблемой, поэтому хотелось бы знать, что можно сделать, чтобы избежать этого огромного скачка значений?
В SQL Server 2019 и более поздних версиях имеется способ отключить кэш, устанавливая параметр IDENTITY_CACHE ON или OFF. Тем самым мы можем избежать такого возможного зазора в столбцах identity. Давайте попробуем!
Сначала мы можем проверить значение этого параметра с помощью простого запроса в следующем примере:
SELECT *
FROM sys.database_scoped_configurations
WHERE NAME = 'IDENTITY_CACHE'Теперь мы можем установить этот параметр в OFF:
ALTER DATABASE SCOPED CONFIGURATION SET IDENTITY_CACHE=OFFДавайте снова проверим этот параметр:
SELECT *
FROM sys.database_scoped_configurations
WHERE NAME = 'IDENTITY_CACHE'А теперь давайте снова попробуем вставить новое значение, а потом спровоцируем неожиданное выключение:
insert into supplier(Companyname,vatcode,address,city,country,email)
values('Granite Austria Inc','123456789','Reisenauer Strasse, 5','Graz','Austria','test@email2.com')SHUTDOWN WITH NOWAIT;Перезапустим службу и выполним этот запрос снова для проверки.
select IDENT_CURRENT('Supplier')Как видно, мы избежали скачка значений. Чтобы быть точным, скажу, что тот же результат мог быть получен в предыдущих выпусках SQL Server при включении флага трассировки 272 для выключения кэша identity, но побочным эффектом этого флага трассировки является выключение кэша identity на уровне сервера, а не на уровне базы данных, как для параметра IDENTITY_CACHE.
Имейте в виду, что отключение кэша identity может привести к проблемам производительности, особенно если у вас имеется множество вставок в таблицы, имеющих столбцы identity, поэтому установка IDENTITY_CACHE в значение OFF должна быть тщательно протестирована, т.к. это потенциально вредно для производительности INSERT.
Oracle
Поскольку в Oracle столбец identity непосредственно вытекает из последовательности (Sequences), имеется возможность указать значение кэша. Значение по умолчанию - 20, и также есть возможность указать NOCACHE, что полностью исключает возможность появления больших зазоров в случае неожиданного краха сервера.
Однако в Oracle мы можем получить большие проблемы с производительностью, если не будем использовать кэш в последовательности и столбцах identity, особенно в окружении RAC. Вкратце, RAC - это аббревиатура для Real Application Cluster (реальный кластер приложений), который обеспечивает высокую доступность Oracle; проверенная технология, в которой у нас обычно имеется два узла, на которых работают два экземпляра базы данных Oracle, и если один выходит из строя, другой берет на себя всю нагрузку. Основное отличе от традиционного кластера SQL Server состоит в том, что оба узла активны; тем самым возможна конкуренция, если оба обращаются за одним и тем же объектом, например, к последовательности/столбцу identity. О RAC можно много говорить, как и о способах избежать конкуренции, например, при использовании различных служб для распределения нагрузки, однако это выходит за рамки данной статьи.
Итак, это основа возможных проблем с производительностью при кэшировании. Использование столбца identity или последовательности без кэша надлежащего размера в окружении Oracle RAC может привести к конкуренции в последовательности, к которой обращаются оба узла RAC. Поэтому всегда рекомендуется совместно с разработчиками приложений проверять, сколько вставок в минуту ожидается для таблицы, использующей столбец identity или последовательности. Очевидно, что мы говорим о больших нагрузках OLTP.
Помимо сказанного выше, мы можем также получить проблемы с зазорами в Oracle при неожиданном отключении (например, SHUTDOWN ABORT), когда Oracle ведет себя аналогично SQL Server, что приводит к скачку в идентификаторах, поскольку значения кэша сбрасываются.
Давайте продемонстрируем это. Мы вставим новую строку в таблицу supplier, но сначала мы должны вернуть на 1 INCREMENT BY, который мы изменили в последнем примере части 1, чтобы было легче проверять идентификаторы:
alter table chinook.supplier modify SupplierId GENERATED BY DEFAULT AS IDENTITY INCREMENT BY 1;
insert into chinook.supplier (companyname,vatcode,Address,city,country,email)
values ('EMI Austria','123456789', 'Klinghofer Strasse, 2', 'Wien','Austria','test@email.com');
commit;Проверим значения:
select * from chinook.supplier;Теперь остановим экземпляр Oracle с опцией ABORT для того, чтобы спровоцировать неожиданное выключение. В моем случае это PDB или Pluggable Database, которая является частью CDB или Container Database (более подробно об архитектуре Multitenant вы можете прочитать здесь).
Имейте в виду, что возможно выполнить Shutdown с опцией Abort в PDB только в режиме Archivelog, что эквивалентно режиму восстановления FULL в SQL Server, но режим Archivelog устанавливается на уровне Container (CDB), и потому он устанавливается для всех PDB в контейнере.
Для выключения PDB мы соединяется с хостом посредством SSH, авторизуемся как пользователь Oracle, и входим в контейнер с помощью sqlplus, проверяя сначала, что переменная ORACLE_SID является именем службы нашей базы данных в контейнере:
Теперь мы можем подключиться с помощью sqlplus:
Теперь мы можем отключить базу данных TEST с помощью команды ALTER DATABASE (работает только на PDB) с опцией ABORT. Пожалуйста, делайте это только в среде тестирования!
Теперь снова откроем её:
И мы получим следующую ошибку:
Для восстановления базы данных после неожиданного отключения мы должны восстановить каждый файл данных, используя его номер:
После восстановления каждого из файлов данных мы можем, наконец, открыть переиздание базы данных:
Теперь мы уже можем проверить текущее значение столбца identity, используя тот же трюк из первой части для проверки последовательности Oracle:
SELECT CHINOOK.ISEQ$$_85607.currval FROM DUAL;Как видно, мы перепрыгнули на 50 номеров точно в соответствии со значением кэша.
Давайте также выполним пример изменения параметра CACHE, опять таки, это простая операция изменения таблицы:
alter table chinook.supplier modify SupplierId GENERATED BY DEFAULT AS IDENTITY NOCACHE;Таким образом, теперь столбец identity больше не будет использовать кэш, очень просто.
PostgreSQL
Мы уже видели в первой части, что PostgreSQL использует своеобразный способ обработки кэша для столбцов identity и последовательностей. В нескольких сессиях, в которых вставляются значения в таблицу, каждая использует свой собственный кэш-пул. Это означает, что всякий раз, когда сессия завершается и создается новая, мы получаем зазор, даже без выключения, не важно какого - внезапного или запланированного.
Давайте рассмотрим пример. До вставки новой строки в таблицу supplier мы сначала установим приращение обратно в 1:
alter table supplier alter column supplierid set increment by 1
insert into supplier (companyname,vatcode,Address,city,country,email)
values ('EMI Austria','123456789', 'Klinghofer Strasse, 2', 'Wien','Austria','test@email.com');Проверим нашу таблицу:
select * from supplier;
Да, я знаю, что мы еще немного поиграли с данными PostgreSQL ранее, как показано выше!
Теперь мы просто закроем сессию, откроем новую и выполним NEXTVAL подобно тому, как мы это делали в первой части:
select nextval(pg_get_serial_sequence('supplier','supplierid'))Мы опять прыгнули на 50 значений в кэше. Таким образом, в PostgreSQL зазоры не только возможны, но почти наверняка появятся, и это справедливо как для столбцов identity, так и для последовательностей.
Преобразовать существующий столбец в столбец identity
Очень легко добавить столбец identity в существующую таблицу, если мы просто добавляем новый столбец, но что если мы хотим взять существующий столбец и преобразовать его в identity? Это может оказаться непросто в случае, если мы хотим корректно сохранить уже хранящиеся в столбце значения.
SQL Server
В SQL Server нет прямого способа выполнить эту задачу, но есть обходной путь.
Можно создать новую отдельную таблицу со столбцом identity и такой же структуры, как и таблица, столбец которой мы хотим преобразовать. Затем установить IDENTITY_INSERT ON, скопировать все данные из старой таблицы в новую и, наконец, удалить старую таблицу и переименовать новую. Конечно это решение зависит от наличия ссылок Foreign Key на таблицу (вам потребуется удалить ограничения, чтобы удалить старую таблицу).
Итак, пусть мы хотим модифицировать столбец ArtistId в таблице Artist в столбец identity. Поэтому мы сначала создадим новую таблицу Temp_Artist с помощью оператора CREATE TABLE:
CREATE TABLE Temp_Artist(
ArtistId int identity(1,1) NOT NULL, -- starting value of 1 and a seed value of 1
[Name] nvarchar(120) NULL,
CONSTRAINT [PK_Artist_new] PRIMARY KEY CLUSTERED
(ArtistId ASC))Теперь установим IDENTITY_INSERT в значение ON:
set identity_insert Temp_Artist onА теперь мы может скопировать значения из одной таблицы в другую:
insert into Temp_Artist(Artistid, name)
select Artistid, name from ArtistПроверим значеня в новой таблице:
select * from temp_artistПоскольку все выглядит нормально, мы можем удалить таблицу Artist:
drop table artistКак ожидалось, мы не можем удалить её, т.к. имеется ссылка Foriegn Key на эту таблицу, поэтому вы должны сначала удалить ограничение. Используя хранимую процедуру SP_FKEYS мы можем проверить, какие ограничения ссылаются на таблицу Artist:
EXEC sp_fkeys @pktable_name = 'Artist'Таким образом, мы можем увидеть, что на столбец ArtistId ссылается ограничение FK_AlbumArtistId, и мы можем удалить его, а потом создать его снова после завершения и переименования новой таблицы:
alter table album drop constraint FK_AlbumArtistIdТеперь мы можем уже удалить старую таблицу:
drop table artistи переименовать старую, для чего мы будем использовать хранимую процедуру SP_RENAME:
EXEC sp_rename 'Temp_Artist', 'Artist';Теперь создадим ограничение внешнего ключа, которое мы удаляли:
ALTER TABLE [dbo].[Album] WITH NOCHECK ADD CONSTRAINT [FK_AlbumArtistId] FOREIGN KEY([ArtistId])
REFERENCES [dbo].[Artist]([ArtistId])
ALTER TABLE [dbo].[Album] CHECK CONSTRAINT [FK_AlbumArtistId]Теперь проверим в таблице столбец identity с помощью IDENT_CURRENT:
select ident_current('Artist')Все сделано, простым обходным путем мы преобразовали существующий столбец в столбец identity, сохранив имеющиеся там значения.
Oracle
В Oracle мы имеем в точности такое же поведение, как в SQL Server, поэтому для преобразования существующего стролбца в столбец identity мы следуем тем же обходным путем и сначала создаем новую таблицу:
CREATE TABLE CHINOOK.TEMP_ARTIST
(ARTISTID NUMBER GENERATED BY DEFAULT AS IDENTITY (START WITH 1 INCREMENT BY 1 CACHE 50) NOT NULL ENABLE,
NAME VARCHAR2(120 BYTE),
CONSTRAINT PK_TEMP_ARTIST PRIMARY KEY (ARTISTID)); Теперь мы можем выполнить вставку в новую таблицу, поскольку мы установили столбец identity генерированным по умолчанию:
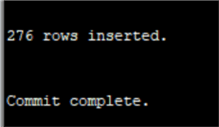
insert into CHINOOK.TEMP_ARTIST (ArtistId, name)
select ArtistId, name from chinook.artist;
commit;Удалите ограничение на таблице Artist. Чтобы получить ссылки на таблицу в Oracle, вот простой запрос, который использует таблицу DBA_CONSTRAINTS:
with foreign_key as
(SELECT c.constraint_name, c.r_constraint_name, c.table_name
FROM dba_constraints c
WHERE constraint_type='R')
SELECT FOREIGN_KEY.table_name,foreign_key.constraint_name as "Constraint Name",
D.TABLE_NAME AS referenced_table_name,d.constraint_name as "Referenced PK"
FROM dba_constraints d inner join
foreign_key on d.constraint_name=foreign_key.r_constraint_name
WHERE D.table_name='ARTIST' AND D.OWNER='CHINOOK';alter table chinook.album drop constraint FK_ALBUMARTISTID;
drop table chinook.artist;Наконец, переименуем нашу новую таблицу и заново создадим ограничение. Для переименования таблицы в Oracle можно использовать оператор ALTER TABLE RENAME:
ALTER TABLE CHINOOK.TEMP_ARTIST RENAME TO artist;alter table chinook.album add CONSTRAINT FK_ALBUMARTISTID FOREIGN KEY (ARTISTID)
REFERENCES CHINOOK.ARTIST (ARTISTID) ENABLE;Теперь давайте проверим значение столбца identity:
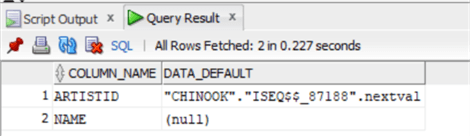
select column_name, data_default from dba_tab_cols
where owner= 'CHINOOK' AND table_name = 'ARTIST';SELECT "CHINOOK"."ISEQ$$_87188".nextval FROM DUAL;В Oracle мы видим, что нам необходимо установить столбец identity, чтобы он начинался с последнего имеющегося значения:
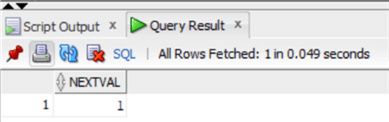
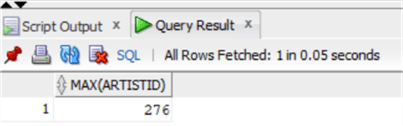
select max(artistid) from chinook.artist;alter table chinook.artist modify artistid generated always as identity (start with 277);Тем самым мы установили наш новый столбец identity!
PostgreSQL
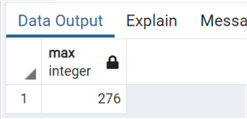
Для PostgreSQL мы имеем другое решение. Есть возможность непосредственно добавить свойство identity для существующего столбца, сохранив предварительные значения. Давайте выполним те же действия на PostgreSQL, изменив ArtistID в таблице Artist. Посмотрим сначала максимальное значение в столбце:
select max("ArtistId") from "Artist"Теперь мы можем изменить столбец, используя обычное ALTER TABLE ADD и указывая в опции START WITH полученное только что число плюс 1:
ALTER TABLE "Artist" ALTER "ArtistId" ADD GENERATED ALWAYS AS IDENTITY (START WITH 277)Посмотрим теперь на значения в таблице:
select * from "Artist"и проверим следующее значение для нашего столбца identity:
select nextval(pg_get_serial_sequence('"'||'Artist'||'"','ArtistId'))Есть! В PostgreSQL это сделать очень легко и может быть сделано непосредственно без проблем!
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой