
Преобразования оптимизатора Oracle
Пересказ статьи Jonathan Lewis. Transformations by the Oracle Optimizer
Общеизвестно, что когда вы пишете оператор SQL, вы сообщаете базе данных что вы хотите, но не как это получить. Тогда неудивительно, что за исключением простейших случаев оператор, который оптимизирует Oracle, не обязательно является тем, который вы писали. Другими словами, Oracle будет, вероятно, преобразовывать ваш оператор в логически эквивалентный оператор, прежде чем применять арифметику, которую он использует для выбора плана выполнения.
Если вы хотите стать специалистом в исправлении плохо выполняющихся запросов SQL, важно понимать, какие преобразования были применены, какие преобразования не были применены, когда они могли бы применяться, и как навязать (или блокировать) преобразования, которые будут иметь наибольшее воздействие.
В этой статье мы собираемся проверить одно из старейших и наиболее часто выполняемых преобразований, которые рассматривает оптимизатор: невложенные подзапросы.
"Блок запроса" является начальной точкой для понимания методов оптимизатора и чтения планов выполнения. Что бы вы ни делали в своем запросе, неважно насколько сложным или путаным он является, оптимизатор хотел бы преобразовать его в эквивалентный запрос вида:
Дополнительно ваш запрос может содержать предложения group by, having и order by, а также любые из различных функций постобработки в более новых версиях Oracle, но основная задача оптимизатора - найти путь, который позволит получить необработанные данные за минимально возможное время. Основная часть обработки оптимизатора сфокусирована на том "что вы хотите" (select), "где это находится" (from), "как мне соединить части" (where). Эта простая структура и является "блоком запроса", и большую часть арифметики оптимизатор производит, вычисляя стоимость выполнения каждого отдельного блока запроса один раз.
Некоторые запросы, конечно, не могут быть сведены к такой простой структуре - вот почему я поместил "таблицы" в кавычки и использовал слово "простые" в описание предикатов. В этом контексте "таблица" может быть "не объединяемым представлением", которое будет изолированным и обрабатываемым как результирующий набор из отдельно оптимизируемого блока запроса. Если Oracle все же оставляет некоторые подзапросы в предложении where или списке select, то лучшее, что он может сделать для преобразования вашего запроса, это изолировать и обработать эти подзапросы как отдельно оптимизируемые блоки запроса.
Когда вы пытаетесь решить проблему при помощи плохо выполняющегося SQL, исключительно полезно идентифицировать отдельные блоки запроса вашего исходного запроса в окончательном плане выполнения. Ваша проблема с производительностью может происходить из того, как Oracle решил "сшить вместе" отдельные блоки запроса, которые он сгенерировал во время построения окончательного плана.
Вот пример запроса, который начинает существование с двух блоков запроса. Обратите внимание на подсказку qb_name(), которую я использовал, чтобы дать явные имена блокам запроса. Если этого не сделать, Oracle использовал бы сгенерированные имена sel$1 и sel$2 для блоков запроса вместо main (главный) and subq (подзапрос) соответственно.
Я создал обе таблицы t1 и t2, используя выборки из представления all_objects с тем, чтобы имена столбцов (и возможные шаблоны данных) выглядели похоже и были осмысленны. Я буду использовать Oracle 12.2.0.1 для получения планов выполнения, который все еще очень распространен, и тут мало что существенно изменилось в версиях вплоть для релиза 19с.
Имеется несколько возможных планов для этого запроса, в зависимости от того, как мой CTAS (CREATE TABLE AS SELECT) фильтровал или масштабировал исходное содержимое all_objects, какие индексы я добавил или удалил какие-либо декларации not null. Я начну с плана выполнения, который я получаю, когда добавляю хинт /*+ no_query_transformation */ к тексту:
Возвращаемый план выглядит подобным образом:
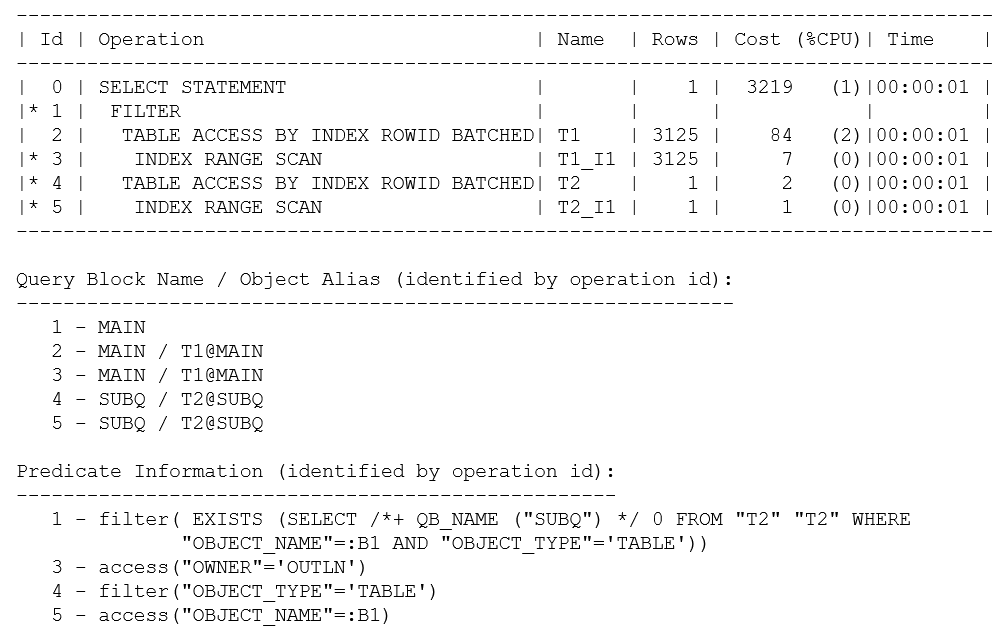
Здесь я использовал explain plan с тем, чтобы вы могли увидеть полную информацию о предикатах (Predicate Information). Если бы я выполнил запрос и вытащил план из памяти с помощью вызова dbms_xplan.display_cursor(), информация о предикатах для операции 1 читалась бы так: “1 – filter( IS NOT NULL)”. Поскольку здесь нет связанных переменных (и нет риска побочных эффектов из-за несовпадающих наборов символов), можно спокойно предположить, что explain plan произведет корректный план.
Есть несколько моментов, на которые стоит обратить внимание в этом запросе и плане:
Хотя я инструктировал оптимизатор не делать преобразования запроса (“no query transformations”), из информации о предикатах для операции 1 видно, что мой некоррелирующий подзапрос в IN был преобразован в коррелирующий подзапрос в EXISTS, где связывалось object_name с переменной (:B1). Здесь нет противоречия между моим хинтом и преобразованием оптимизатора - это пример "эвристической" трансформации (т.е. оптимизатор сделает это, потому что есть правило, говорящее, что он может), а хинт относится только к преобразованиям на основе стоимости.
Информация “alias” (псевдоним), которую я запросил при вызове dbms_xplan.display(), привела к выводу раздела плана Query Block Name / Object Alias. Этот раздел позволяет увидеть, что план был составлен из двух блоков запроса (main и subq), которым я дал имена в исходном тексте. Вы можете увидеть, что t1 и t1_i1, появляющиеся в теле плана, соответствуют t1, который появился в главном блоке запроса (t1@main), а t2/t2_i1 соответствует t2 в блоке запроса subq (t2@subq). Это примитивное наблюдение в данном случае, но если, например, вы разбираетесь с длинным запутанным запросом в схеме Oracle General Ledger, очень полезной будет возможность определить, где в запросе возникла каждая из множества ссылок на часто используемый GLCC.
Если вы исследуете основную форму плана, то увидите, что блок запроса main был выполнен сканированием диапазона индекса на основе предиката object_name = {bind variable}. Oracle затем сшил вместе эти два блока запроса через операцию filter. Для каждой строки, возвращаемой блоком запроса main операция filter выполняет блок запроса subq, чтобы посмотреть, может ли он найти совпадающий object_name, который также имеет тип TABLE.
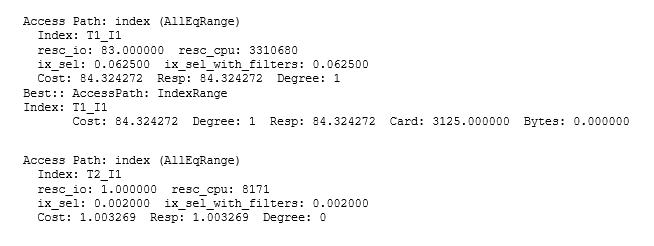
Наконец, комментарий относительно стоимости (Cost): если все, что вы можете видеть, это план выполнения, легко впасть в заблуждение эффектами округления и скрытыми деталями оптимизатора, допускающими «самовозникающее кэширование» и т.д. В этом случае базовая стоимость 2 для каждого выполнения подзапроса сводится до 1 в предположении, что корневой блок индекса будет кэширован, а быстрая проверка файла трассировки CBO (трассировка 10053) показывает, что 1 фактически ближе к 1.003 (а 84 для доступа t1 оказывается фактически 84.32). Поскольку оптимизатор имел оценку в 3125 строк для числа строк, которые он будет сначала считывать из t1 до применения фильтрации, общая предсказанная стоимость 3219 есть приблизительно: 84.32+ 3125 * 1.003. Конечно, реально ожидать, что будет кэшировано значительно больше данных со значительно сниженной нагрузкой ввода-вывода; особенно в данном случае, когда общий размер таблицы t2 занимал только 13 блоков, поэтому вычисление, дающее оценку стоимости, эквивалентную более чем 3000 физическим чтениям для повторяющегося выполнения подзапроса, явно несостоятельно. Более того, оптимизатор не пытается разрешить функцию, известную как кэширование скалярного подзапроса, поэтому арифметика опирается на предположение, что подзапрос t2 будет выполняться для каждой строки, найденной в t1.
Вот раздел из файла трассировки CBO:
Оптимизатор трансформировал подзапрос IN в подзапрос EXISTS. Если значение object_name в строке из t1 важно, когда оно появляется в списке значений, тогда разумно проверить нахождение этого значения в списке. Если список содержит дубликаты, поиск останавливается после нахождения первого совпадения. Это фактически метод операции FILTER в исходном плане, но имеется альтернатива. Если оказывается, что наборы данных имеют правый шаблон и объем, Oracle может выполнить практически те же действия, но использовать semi_join, что означает "для каждой строки в t1 найти первую совпадающую строку в t2". План будет выглядеть следующим образом:
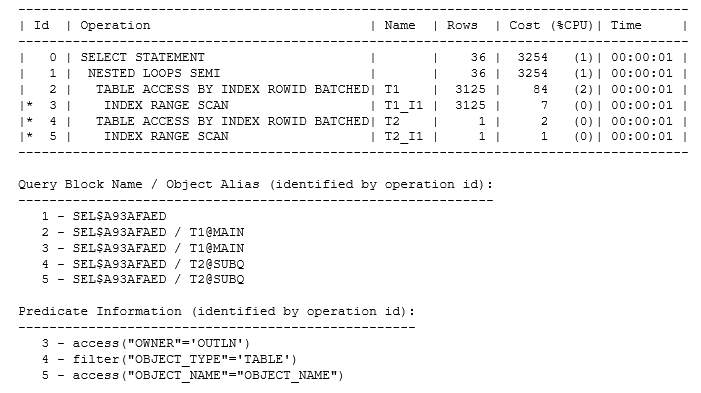
Самосоединение было фактической стратегией, которую выбрал оптимизатор для моего исходного набора данных, когда я позволил, чтобы имела место оптимизация на основе стоимости, но использовалось хэш-соединение, а не соединение вложенными циклами. Поскольку t2 был источником с меньшими строкам, Oracle "поменял стороны", чтобы получить хэш-соединение (hash join), которое явилось одновременно "полу" (semi) и "правое" (right):

Объемы участвующих данных могут привести к идее принять совершенно отличную стратегию - когда разделение становится очевидным. Если объем данных данных из t1 настолько мал, что вам нужно всего лишь запустить проверку несколько раз, то тест наличия может оказаться очень хорошей идеей (особенно, если имеется индекс, который поддерживает очень эффективную проверку). Если объем данных из t1 велик или нет эффективного способа выполнить проверку в таблице t2, то, возможно, будет лучше создать список различающихся значений (object_name) в t2 и использовать этот список для выполнения соединения с t1. Вот один пример того, как может измениться план:
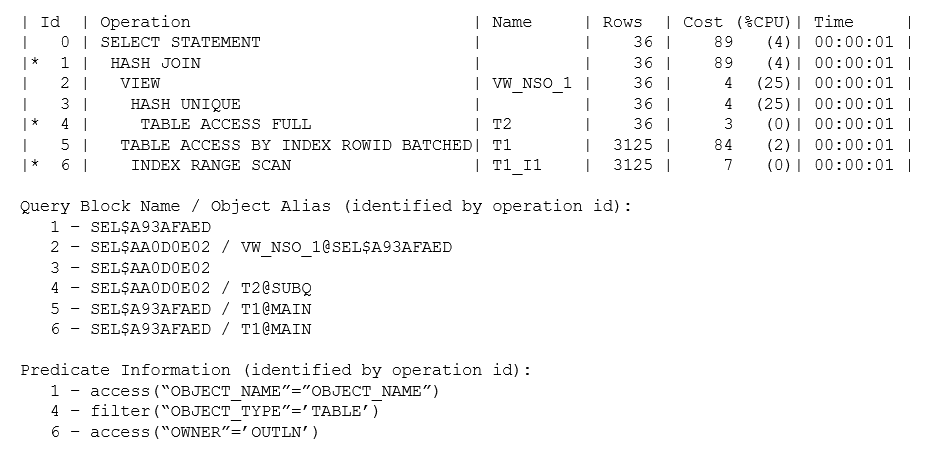
Теперь план имеет новый объект в операции 2, (несливаемое) представление с именем vw_nso_1, которое узнаваемо содержит различные (hash unique) значения t2.object_name. Число таких значений весьма мало (по оценке только 36), поэтому оптимизатор мог использовать соединение вложенными циклами (nested loop join) для выбора связанных строк из t1, но арифметика подтолкнула его к использованию метода «грубой силы» для поиска всех строк t1 типа TABLE, а затем выполнения хэш-соединения.
Важно взять себе за правило использовать опцию форматирования alias, когда форма плана не соответствует образцу, который вы ожидали увидеть. В этом случае вы можете увидеть из информации Query Block Name (имя блока запроса), что окончательный план состоит из двух новых блоков запроса: sel$aa0d0e02 и sel$a93afaed. Первый блок запроса описывает, как Oracle будет создавать "табличное" представление списка различных имен объектов, а второй блок запроса является простым соединением двух "таблиц" с помощью хэш-соединения. Обратите внимание, как информация Object Alias говорит вам, что представление vw_nso_1 возникает с блоке запроса sel$a93afaed.
Примечание: Сгенерированное имя блока запроса представляет собой хэш-значение, сгенерированное из имен блоков запроса, которые использовались для создания нового блока запроса, а функция хеширования является детерминированной.
В результате исходный запрос был преобразован к такому эквивалентному виду:
Всякий раз, когда вы видите представление в плане с именем, подобным vw_nso_{число}, это говорит о том, что оптимизатор преобразовал подзапрос IN в таким образом встроенный подзапрос. Интересно, что если вы вручную перепишите запрос для замены подзапроса IN на подзапрос EXISTS, то обнаружите, что вы получите в точности тот же план, но с представлением под именем vw_sq_{число}.
И даже эта стратегия может быть подвергнута дальнейшей трансформации, если шаблон данных оправдывает это. В моем тестовом случае оптимизатор делает “distinct aggregation” (агрегацию уникальных значений) на числе небольших строк перед соединением с другой таблицей для производства значительно больших строк, что означает, что шаг агрегации может быть довольно эффективным. Но что, если агрегироваться будет большое число строк в t2, и если строки были близки к уникальным и оказались довольно длинными – шаг агрегации может потребовать много работы с очень небольшим выигрышем. Если соединение с t1 затем устраняло множество (агрегированных) данных t2, а строки t1 в списке select были довольно короткими, возможно, более эффективным может стать соединение t1 и t2 для устранения множества длинных строк до агрегации для исключения дубликатов, что приведет к следующему плану:
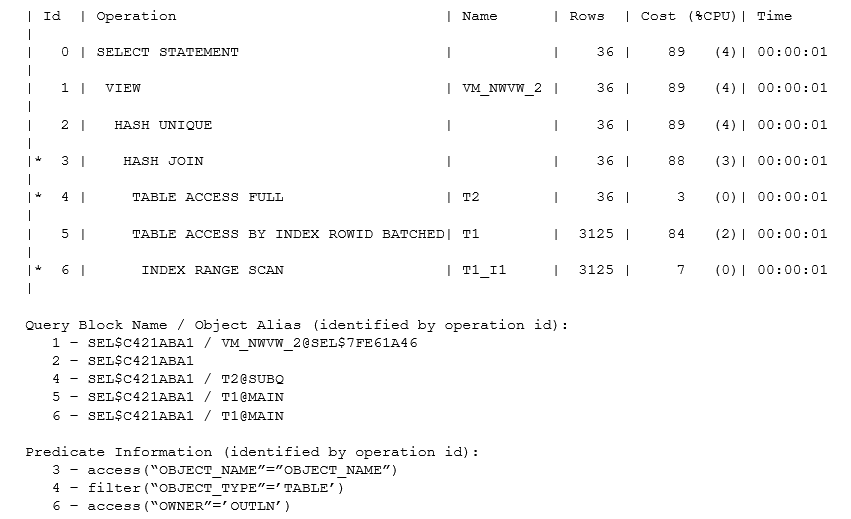
Как видно, оптимизатор выполнил хэш-соединение t1 и t2 до устранения дубликатов с помощью операции “hash unique”. Это немного более тонко, чем выглядит, поскольку, если вы попытаетесь написать оператор для этого, то можете легко допустить ошибку, которая исключит некоторые строки, которые следовало бы сохранить - ошибка лучше всего объясняется путем изучения примерного эквивалента оператора, который Oracle фактически оптимизировал:
Обратите внимание на присутствие t1.rowid во встроенном представлении; это критическая часть, которая защищает Oracle от получения неправильных результатов. Поскольку соединение выполняется по object_name (которое не является уникальным в представлении all_objects, на базе которого я создавал мои таблицы), может оказаться две строки в t1 и две - в t2, все содержащие тоже самое object_name, что приведет к тому, что простое соединение даст четыре строки.
Окончательный результирующий набор должен содержать две строки (в соответствии с исходными двумя строками t1), но если оптимизатор не включил rowid таблицы t1 в список select до использования оператора distinct, эти четыре строки должны сгруппироваться в единственную строку. Оптимизатору иногда приходится выполнять очень сложную (или, возможно, непонятную) работу для получения корректно трансформированного оператора - вот почему в документации иногда перечисляются ограничения для новых трансформаций: более тонкие фрагменты кода, которые гарантировали бы правильные результаты для конкретных случаев, не всегда появляются в первом выпуске нового преобразования.
Обратите внимание, что сгенерированное в данном случае имя представления имеет вид vm_nwvw_{число}. Большая часть сгенерированных имен представлений начинается с vw_, этот случай является особым. Представление показывает один из эффектов “Complex View Merging” (слияние сложных представлений) - отсюда и vm, возможно - где Oracle меняет “aggregate then join” (агрегация, затем соединение) на “join then aggregate” (соединение, затем агрегация), что происходит довольно часто как шаг после распаковки подзапроса.
Если вы пишете запрос, содержащий подзапросы, будь то в списке select или (что более часто) в предложении where, оптимизатор будет часто рассматривать возможность удаления как можно большего числа подзапросов. Это обычно означает встраивание вашего подзапроса в представление, которое может войти в предложение from и соединяться с другими таблицами в предложении from.
Имена таких встроенных представлений обычно имеют вид vw_nso_{число} или vw_sq_{число}.
После удаления подзапроса Oracle может применить дальнейшие преобразования, которые делают встроенное представление "исчезающим" - включением его в соединение или полусоединение, или (пример, который мы не рассматривали) антисоединение. Как альтернатива, встроенное представление может также быть подвергнуто слиянию сложных представлений, что может привести к появлению нового представления с именем типа vm_nwvw_{число}, но может привести к исчезновению любой операции с представлением.
Я не рассматривал тему возможностей Oracle при обработке соединений с невложенным представлением, если оно оказывается несливаемым, и я ничего не говорил о различиях между подзапросами IN и NOT IN. Это темы для другой статьи.
Наконец, я начал статью с обсуждения "блока запроса" и его важности для оптимизатора. При написании запроса хорошо давать каждому блоку запроса его собственное имя, используя хинт qb_name(). Когда вам потребуется исследовать план выполнения, рекомендуется добавить параметр формата псевдонима в вызов dbms_xplan, чтобы вы могли обнаружить свои исходные блоки запроса в окончательном плане и увидеть, какие части плана представляют блоки запроса, созданные оптимизатором при преобразовании, а также границы, где оптимизатор «сшил вместе» отдельные блоки запроса.
Если вы исследовали детально эти планы выполнения, то обнаружили, что все пять планов выглядят так, как будто они были произведены из в точности одинаковых таблиц - хотя мои заметки касались того, как разные планы для одного и того же запроса могут появляться из-за разных шаблонов в данных. Для демонстрации различных планов я использовал минимальное число хинтов с целью изменить выбор оптимизатора. В конечном счете, когда оптимизатор допустил ошибку при выборе преобразования, вам нужно знать, как распознать и контролировать преобразования, и вам, возможно, придется использовать хинты в вашем рабочем коде.
Я часто предупреждал людей насчет использования хинтов из-за сложности делать это правильно, но хинты, предназначенные для блоков запроса (уровень, где играет роль выбор преобразования) значительно безопасней, чем использование хинтов "микро-обслуживания" на уровне объектов.
Хотя я использовал хинты "микро-обслуживания" (объектный уровень) для переключения между соединения вложенными циклами и хэш-соединенем в разделе "Вариации на тему", во всех других примерах использовались хинты блоков запроса, а именно: merge/no_merge, unnest/no_unnest или semijoin/no_semijoin.
В этой статье мы собираемся проверить одно из старейших и наиболее часто выполняемых преобразований, которые рассматривает оптимизатор: невложенные подзапросы.
Список желаний оптимизатора
"Блок запроса" является начальной точкой для понимания методов оптимизатора и чтения планов выполнения. Что бы вы ни делали в своем запросе, неважно насколько сложным или путаным он является, оптимизатор хотел бы преобразовать его в эквивалентный запрос вида:
select {список столбцов}
from {список “таблиц”}
where {список простых соединений и предикатов фильтрации}Дополнительно ваш запрос может содержать предложения group by, having и order by, а также любые из различных функций постобработки в более новых версиях Oracle, но основная задача оптимизатора - найти путь, который позволит получить необработанные данные за минимально возможное время. Основная часть обработки оптимизатора сфокусирована на том "что вы хотите" (select), "где это находится" (from), "как мне соединить части" (where). Эта простая структура и является "блоком запроса", и большую часть арифметики оптимизатор производит, вычисляя стоимость выполнения каждого отдельного блока запроса один раз.
Некоторые запросы, конечно, не могут быть сведены к такой простой структуре - вот почему я поместил "таблицы" в кавычки и использовал слово "простые" в описание предикатов. В этом контексте "таблица" может быть "не объединяемым представлением", которое будет изолированным и обрабатываемым как результирующий набор из отдельно оптимизируемого блока запроса. Если Oracle все же оставляет некоторые подзапросы в предложении where или списке select, то лучшее, что он может сделать для преобразования вашего запроса, это изолировать и обработать эти подзапросы как отдельно оптимизируемые блоки запроса.
Когда вы пытаетесь решить проблему при помощи плохо выполняющегося SQL, исключительно полезно идентифицировать отдельные блоки запроса вашего исходного запроса в окончательном плане выполнения. Ваша проблема с производительностью может происходить из того, как Oracle решил "сшить вместе" отдельные блоки запроса, которые он сгенерировал во время построения окончательного плана.
Пример использования
Вот пример запроса, который начинает существование с двух блоков запроса. Обратите внимание на подсказку qb_name(), которую я использовал, чтобы дать явные имена блокам запроса. Если этого не сделать, Oracle использовал бы сгенерированные имена sel$1 и sel$2 для блоков запроса вместо main (главный) and subq (подзапрос) соответственно.
select /*+ qb_name(main) */
*
from t1
where owner = 'OUTLN'
and object_name in (
select /*+ qb_name(subq) */
object_name
from t2
where object_type = 'TABLE'
)
;Я создал обе таблицы t1 и t2, используя выборки из представления all_objects с тем, чтобы имена столбцов (и возможные шаблоны данных) выглядели похоже и были осмысленны. Я буду использовать Oracle 12.2.0.1 для получения планов выполнения, который все еще очень распространен, и тут мало что существенно изменилось в версиях вплоть для релиза 19с.
Имеется несколько возможных планов для этого запроса, в зависимости от того, как мой CTAS (CREATE TABLE AS SELECT) фильтровал или масштабировал исходное содержимое all_objects, какие индексы я добавил или удалил какие-либо декларации not null. Я начну с плана выполнения, который я получаю, когда добавляю хинт /*+ no_query_transformation */ к тексту:
explain plan for
select /*+ qb_name(main) no_query_transformation */
*
from t1
where owner = 'sys'
and object_name in (
select /*+ qb_name(subq) */
object_name
from t2
where object_type = 'TABLE'
)
;
select * from table(dbms_xplan.display(format=>'alias -bytes'));Возвращаемый план выглядит подобным образом:
Здесь я использовал explain plan с тем, чтобы вы могли увидеть полную информацию о предикатах (Predicate Information). Если бы я выполнил запрос и вытащил план из памяти с помощью вызова dbms_xplan.display_cursor(), информация о предикатах для операции 1 читалась бы так: “1 – filter( IS NOT NULL)”. Поскольку здесь нет связанных переменных (и нет риска побочных эффектов из-за несовпадающих наборов символов), можно спокойно предположить, что explain plan произведет корректный план.
Есть несколько моментов, на которые стоит обратить внимание в этом запросе и плане:
Хотя я инструктировал оптимизатор не делать преобразования запроса (“no query transformations”), из информации о предикатах для операции 1 видно, что мой некоррелирующий подзапрос в IN был преобразован в коррелирующий подзапрос в EXISTS, где связывалось object_name с переменной (:B1). Здесь нет противоречия между моим хинтом и преобразованием оптимизатора - это пример "эвристической" трансформации (т.е. оптимизатор сделает это, потому что есть правило, говорящее, что он может), а хинт относится только к преобразованиям на основе стоимости.
Информация “alias” (псевдоним), которую я запросил при вызове dbms_xplan.display(), привела к выводу раздела плана Query Block Name / Object Alias. Этот раздел позволяет увидеть, что план был составлен из двух блоков запроса (main и subq), которым я дал имена в исходном тексте. Вы можете увидеть, что t1 и t1_i1, появляющиеся в теле плана, соответствуют t1, который появился в главном блоке запроса (t1@main), а t2/t2_i1 соответствует t2 в блоке запроса subq (t2@subq). Это примитивное наблюдение в данном случае, но если, например, вы разбираетесь с длинным запутанным запросом в схеме Oracle General Ledger, очень полезной будет возможность определить, где в запросе возникла каждая из множества ссылок на часто используемый GLCC.
Если вы исследуете основную форму плана, то увидите, что блок запроса main был выполнен сканированием диапазона индекса на основе предиката object_name = {bind variable}. Oracle затем сшил вместе эти два блока запроса через операцию filter. Для каждой строки, возвращаемой блоком запроса main операция filter выполняет блок запроса subq, чтобы посмотреть, может ли он найти совпадающий object_name, который также имеет тип TABLE.
Наконец, комментарий относительно стоимости (Cost): если все, что вы можете видеть, это план выполнения, легко впасть в заблуждение эффектами округления и скрытыми деталями оптимизатора, допускающими «самовозникающее кэширование» и т.д. В этом случае базовая стоимость 2 для каждого выполнения подзапроса сводится до 1 в предположении, что корневой блок индекса будет кэширован, а быстрая проверка файла трассировки CBO (трассировка 10053) показывает, что 1 фактически ближе к 1.003 (а 84 для доступа t1 оказывается фактически 84.32). Поскольку оптимизатор имел оценку в 3125 строк для числа строк, которые он будет сначала считывать из t1 до применения фильтрации, общая предсказанная стоимость 3219 есть приблизительно: 84.32+ 3125 * 1.003. Конечно, реально ожидать, что будет кэшировано значительно больше данных со значительно сниженной нагрузкой ввода-вывода; особенно в данном случае, когда общий размер таблицы t2 занимал только 13 блоков, поэтому вычисление, дающее оценку стоимости, эквивалентную более чем 3000 физическим чтениям для повторяющегося выполнения подзапроса, явно несостоятельно. Более того, оптимизатор не пытается разрешить функцию, известную как кэширование скалярного подзапроса, поэтому арифметика опирается на предположение, что подзапрос t2 будет выполняться для каждой строки, найденной в t1.
Вот раздел из файла трассировки CBO:
Вариации на тему
Оптимизатор трансформировал подзапрос IN в подзапрос EXISTS. Если значение object_name в строке из t1 важно, когда оно появляется в списке значений, тогда разумно проверить нахождение этого значения в списке. Если список содержит дубликаты, поиск останавливается после нахождения первого совпадения. Это фактически метод операции FILTER в исходном плане, но имеется альтернатива. Если оказывается, что наборы данных имеют правый шаблон и объем, Oracle может выполнить практически те же действия, но использовать semi_join, что означает "для каждой строки в t1 найти первую совпадающую строку в t2". План будет выглядеть следующим образом:
Самосоединение было фактической стратегией, которую выбрал оптимизатор для моего исходного набора данных, когда я позволил, чтобы имела место оптимизация на основе стоимости, но использовалось хэш-соединение, а не соединение вложенными циклами. Поскольку t2 был источником с меньшими строкам, Oracle "поменял стороны", чтобы получить хэш-соединение (hash join), которое явилось одновременно "полу" (semi) и "правое" (right):
Но еще кое-что
Объемы участвующих данных могут привести к идее принять совершенно отличную стратегию - когда разделение становится очевидным. Если объем данных данных из t1 настолько мал, что вам нужно всего лишь запустить проверку несколько раз, то тест наличия может оказаться очень хорошей идеей (особенно, если имеется индекс, который поддерживает очень эффективную проверку). Если объем данных из t1 велик или нет эффективного способа выполнить проверку в таблице t2, то, возможно, будет лучше создать список различающихся значений (object_name) в t2 и использовать этот список для выполнения соединения с t1. Вот один пример того, как может измениться план:
Теперь план имеет новый объект в операции 2, (несливаемое) представление с именем vw_nso_1, которое узнаваемо содержит различные (hash unique) значения t2.object_name. Число таких значений весьма мало (по оценке только 36), поэтому оптимизатор мог использовать соединение вложенными циклами (nested loop join) для выбора связанных строк из t1, но арифметика подтолкнула его к использованию метода «грубой силы» для поиска всех строк t1 типа TABLE, а затем выполнения хэш-соединения.
Важно взять себе за правило использовать опцию форматирования alias, когда форма плана не соответствует образцу, который вы ожидали увидеть. В этом случае вы можете увидеть из информации Query Block Name (имя блока запроса), что окончательный план состоит из двух новых блоков запроса: sel$aa0d0e02 и sel$a93afaed. Первый блок запроса описывает, как Oracle будет создавать "табличное" представление списка различных имен объектов, а второй блок запроса является простым соединением двух "таблиц" с помощью хэш-соединения. Обратите внимание, как информация Object Alias говорит вам, что представление vw_nso_1 возникает с блоке запроса sel$a93afaed.
В результате исходный запрос был преобразован к такому эквивалентному виду:
select
t1.*
from (
select
distinct object_name
from t2
where object_type='TABLE'
) vw_nso_1,
t1
where t1.owner='OUTLN'
and t1.object_name = vw_nso_1.object_name
/Всякий раз, когда вы видите представление в плане с именем, подобным vw_nso_{число}, это говорит о том, что оптимизатор преобразовал подзапрос IN в таким образом встроенный подзапрос. Интересно, что если вы вручную перепишите запрос для замены подзапроса IN на подзапрос EXISTS, то обнаружите, что вы получите в точности тот же план, но с представлением под именем vw_sq_{число}.
И даже эта стратегия может быть подвергнута дальнейшей трансформации, если шаблон данных оправдывает это. В моем тестовом случае оптимизатор делает “distinct aggregation” (агрегацию уникальных значений) на числе небольших строк перед соединением с другой таблицей для производства значительно больших строк, что означает, что шаг агрегации может быть довольно эффективным. Но что, если агрегироваться будет большое число строк в t2, и если строки были близки к уникальным и оказались довольно длинными – шаг агрегации может потребовать много работы с очень небольшим выигрышем. Если соединение с t1 затем устраняло множество (агрегированных) данных t2, а строки t1 в списке select были довольно короткими, возможно, более эффективным может стать соединение t1 и t2 для устранения множества длинных строк до агрегации для исключения дубликатов, что приведет к следующему плану:
Как видно, оптимизатор выполнил хэш-соединение t1 и t2 до устранения дубликатов с помощью операции “hash unique”. Это немного более тонко, чем выглядит, поскольку, если вы попытаетесь написать оператор для этого, то можете легко допустить ошибку, которая исключит некоторые строки, которые следовало бы сохранить - ошибка лучше всего объясняется путем изучения примерного эквивалента оператора, который Oracle фактически оптимизировал:
select
{list of t1 columns}
from (
select
distinct
t2.object_name t2_object_name,
t1.rowid _owed,
t1.*
from
t2,
t1
where
t1.owner = 'OUTLN'
and t2.object_name = t1.object_name
and t2.object_type = 'TABLE'
) vm_nwvw_2
;Обратите внимание на присутствие t1.rowid во встроенном представлении; это критическая часть, которая защищает Oracle от получения неправильных результатов. Поскольку соединение выполняется по object_name (которое не является уникальным в представлении all_objects, на базе которого я создавал мои таблицы), может оказаться две строки в t1 и две - в t2, все содержащие тоже самое object_name, что приведет к тому, что простое соединение даст четыре строки.
Окончательный результирующий набор должен содержать две строки (в соответствии с исходными двумя строками t1), но если оптимизатор не включил rowid таблицы t1 в список select до использования оператора distinct, эти четыре строки должны сгруппироваться в единственную строку. Оптимизатору иногда приходится выполнять очень сложную (или, возможно, непонятную) работу для получения корректно трансформированного оператора - вот почему в документации иногда перечисляются ограничения для новых трансформаций: более тонкие фрагменты кода, которые гарантировали бы правильные результаты для конкретных случаев, не всегда появляются в первом выпуске нового преобразования.
Обратите внимание, что сгенерированное в данном случае имя представления имеет вид vm_nwvw_{число}. Большая часть сгенерированных имен представлений начинается с vw_, этот случай является особым. Представление показывает один из эффектов “Complex View Merging” (слияние сложных представлений) - отсюда и vm, возможно - где Oracle меняет “aggregate then join” (агрегация, затем соединение) на “join then aggregate” (соединение, затем агрегация), что происходит довольно часто как шаг после распаковки подзапроса.
Выводы
Если вы пишете запрос, содержащий подзапросы, будь то в списке select или (что более часто) в предложении where, оптимизатор будет часто рассматривать возможность удаления как можно большего числа подзапросов. Это обычно означает встраивание вашего подзапроса в представление, которое может войти в предложение from и соединяться с другими таблицами в предложении from.
Имена таких встроенных представлений обычно имеют вид vw_nso_{число} или vw_sq_{число}.
После удаления подзапроса Oracle может применить дальнейшие преобразования, которые делают встроенное представление "исчезающим" - включением его в соединение или полусоединение, или (пример, который мы не рассматривали) антисоединение. Как альтернатива, встроенное представление может также быть подвергнуто слиянию сложных представлений, что может привести к появлению нового представления с именем типа vm_nwvw_{число}, но может привести к исчезновению любой операции с представлением.
Я не рассматривал тему возможностей Oracle при обработке соединений с невложенным представлением, если оно оказывается несливаемым, и я ничего не говорил о различиях между подзапросами IN и NOT IN. Это темы для другой статьи.
Наконец, я начал статью с обсуждения "блока запроса" и его важности для оптимизатора. При написании запроса хорошо давать каждому блоку запроса его собственное имя, используя хинт qb_name(). Когда вам потребуется исследовать план выполнения, рекомендуется добавить параметр формата псевдонима в вызов dbms_xplan, чтобы вы могли обнаружить свои исходные блоки запроса в окончательном плане и увидеть, какие части плана представляют блоки запроса, созданные оптимизатором при преобразовании, а также границы, где оптимизатор «сшил вместе» отдельные блоки запроса.
Сноска
Если вы исследовали детально эти планы выполнения, то обнаружили, что все пять планов выглядят так, как будто они были произведены из в точности одинаковых таблиц - хотя мои заметки касались того, как разные планы для одного и того же запроса могут появляться из-за разных шаблонов в данных. Для демонстрации различных планов я использовал минимальное число хинтов с целью изменить выбор оптимизатора. В конечном счете, когда оптимизатор допустил ошибку при выборе преобразования, вам нужно знать, как распознать и контролировать преобразования, и вам, возможно, придется использовать хинты в вашем рабочем коде.
Я часто предупреждал людей насчет использования хинтов из-за сложности делать это правильно, но хинты, предназначенные для блоков запроса (уровень, где играет роль выбор преобразования) значительно безопасней, чем использование хинтов "микро-обслуживания" на уровне объектов.
Хотя я использовал хинты "микро-обслуживания" (объектный уровень) для переключения между соединения вложенными циклами и хэш-соединенем в разделе "Вариации на тему", во всех других примерах использовались хинты блоков запроса, а именно: merge/no_merge, unnest/no_unnest или semijoin/no_semijoin.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой