
Почему типы данных MAX обычно оказываются плохим выбором для столбцов SQL Server
Пересказ статьи Erik Darling. Why MAX Data Types Are Usually A Bad Choice For SQL Server Columns
Когда вы пытаетесь выяснить как хранить строковые данные, часто кажется самым простым вариантом выбрать очень длинный - даже MAX - тип данных, чтобы избежать впоследствии ошибок усечения.
Даже если вы сохраняете строки известной абсолютной длины, разработчики могут не использовать это в приложении либо посредством раскрывающегося меню, либо с помощью другой формы проверки.
И поэтому, чтобы избежать ошибок, когда пользователи пытаются поместить свои уж очень важные данные в свою уж очень дорогую базу данных, мы добавляем в таблицу столбцы, которые могут вместить в себя целую галактику данных, тогда как нам нужно всего лишь хранить данные объемом с пепельницу.
В то время как занести данные в эти столбцы относительно легко - большинство приложений вставляют отдельные строки - выборка данных из этих столбцов может стать довольно болезненной, будь то поиск в них, или простое представление в предложении SELECT запроса.
Давайте рассмотрим на паре примеров, что тут происходит.
Возьмем такой запрос:
Столбец Body в таблице Posts является nvarchar и MAX, но то же самое произошло бы и со столбцом varchar.
Двигаемся дальше - в то время как много было написано о ведущих подстановочных знаках при поиске (что начинаются с %), мы не делаем этого здесь. Также, как правило, использование charindex или patindex вместо ведущего подстановочного знака в поиске LIKE не даст вам большого выигрыша (если вообще что-нибудь даст).
В любой случае, поскольку вы не помещали тип данных MAX в ключ индекса, частично проблемы с ними связаны тем, что нет способа эффективно организовать данные для поиска. Включенные столбцы не решают проблемы, поэтому мы приходим к плану, который выглядит как-то так:

Мы тратим ~13,5 секунд на сканирование кластеризованного индекса на таблице Posts, а затем около двух минут и двадцати семи секунд (минус исходные 13,5) на применение предиката, ищущего посты, которые начинаются с SQL Server.
Это довольно таки много для нахождения и возвращения 19 строк.
Давайте немного изменим запрос и взглянем на то, как еще столбцы с длинными строками могут вызвать проблемы.
Вместо поиска по столбцу Body давайте выберем некоторые значения из его, упорядочив их по столбцу Score.
Поскольку Score не проиндексирован, он не отсортирован в базе данных. Это означает, что SQL Server необходимо запросить память для размещения данных, которые мы выбираем в запрашиваемом порядке.
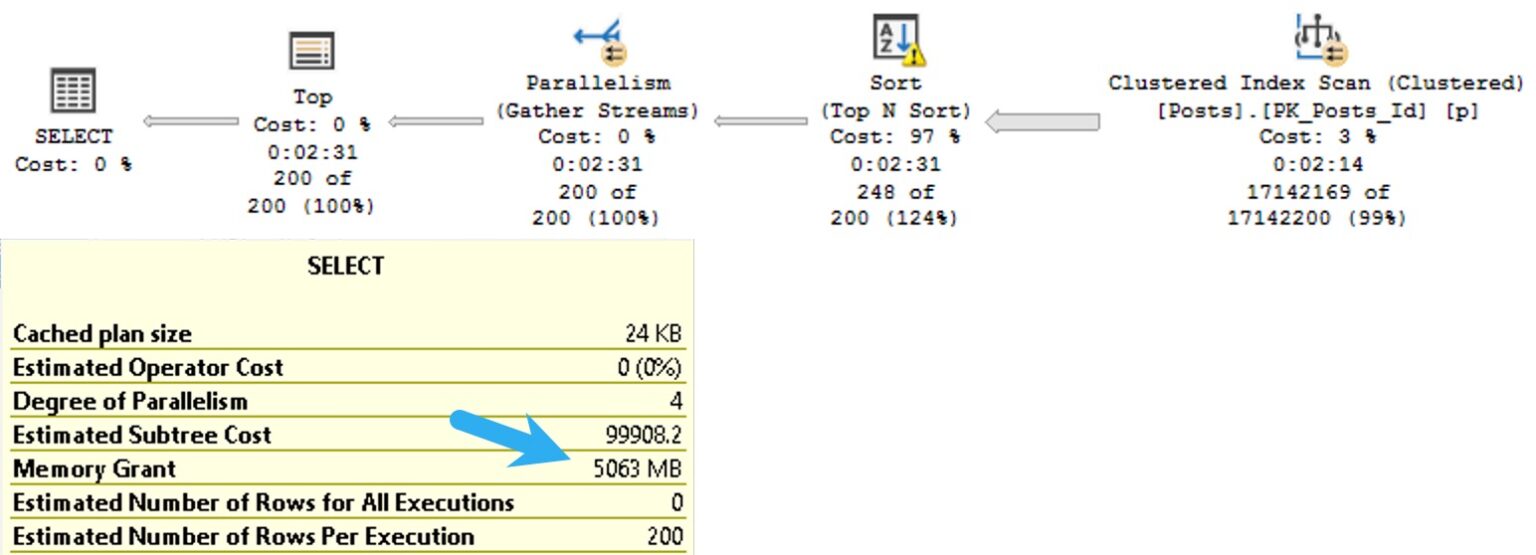
План для этого запроса запрашивает выделения 5Гб памяти:
Я знаю, что вы думаете: вероятно, столбец Body содержит довольно большие данные, и вы правы. В этом случае следует использовать правильный тип данных.
Плохая новость заключается в том, что SQL Server будет делать такую же оценку по выделению памяти на основе размера данных, которые нам требуется сортировать, хорошо это или плохо.
В то время как занести данные в эти столбцы относительно легко - большинство приложений вставляют отдельные строки - выборка данных из этих столбцов может стать довольно болезненной, будь то поиск в них, или простое представление в предложении SELECT запроса.
Давайте рассмотрим на паре примеров, что тут происходит.
Поисковый движок
Возьмем такой запрос:
SELECT TOP (20)
p.Id,
p.Title,
p.Body
FROM dbo.Posts AS p
WHERE p.Body LIKE N'SQL Server%';Столбец Body в таблице Posts является nvarchar и MAX, но то же самое произошло бы и со столбцом varchar.
Двигаемся дальше - в то время как много было написано о ведущих подстановочных знаках при поиске (что начинаются с %), мы не делаем этого здесь. Также, как правило, использование charindex или patindex вместо ведущего подстановочного знака в поиске LIKE не даст вам большого выигрыша (если вообще что-нибудь даст).
В любой случае, поскольку вы не помещали тип данных MAX в ключ индекса, частично проблемы с ними связаны тем, что нет способа эффективно организовать данные для поиска. Включенные столбцы не решают проблемы, поэтому мы приходим к плану, который выглядит как-то так:
Мы тратим ~13,5 секунд на сканирование кластеризованного индекса на таблице Posts, а затем около двух минут и двадцати семи секунд (минус исходные 13,5) на применение предиката, ищущего посты, которые начинаются с SQL Server.
Это довольно таки много для нахождения и возвращения 19 строк.
Давайте немного изменим запрос и взглянем на то, как еще столбцы с длинными строками могут вызвать проблемы.
Банк памяти
Вместо поиска по столбцу Body давайте выберем некоторые значения из его, упорядочив их по столбцу Score.
Поскольку Score не проиндексирован, он не отсортирован в базе данных. Это означает, что SQL Server необходимо запросить память для размещения данных, которые мы выбираем в запрашиваемом порядке.
SELECT TOP (200)
p.Body
FROM dbo.Posts AS p
ORDER BY p.Score DESC;План для этого запроса запрашивает выделения 5Гб памяти:
Я знаю, что вы думаете: вероятно, столбец Body содержит довольно большие данные, и вы правы. В этом случае следует использовать правильный тип данных.
Плохая новость заключается в том, что SQL Server будет делать такую же оценку по выделению памяти на основе размера данных, которые нам требуется сортировать, хорошо это или плохо.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой