
Оптимизация запросов в MySQL: оптимизация чтений
Пересказ статьи Lukas Vileikis. Optimizing Queries in MySQL: Optimizing Reads
Оптимизация операций чтения является одной из наиболее частых проблем, с которой сталкивается любой администратор баз данных. Не важно, какая система управления базами данных используется - MySQL, ее клоны Percona Server или MariaDB, MongoDB, TimescaleDB, SQL Server, или какие-либо другие, запросы на чтение касаются их всех. В первую очередь, можно привести примеры запросов SELECT, но многое также относится к UPDATE и DELETE, поскольку эти операторы тоже должны извлекать строки для работы с ними.
В этом блоге мы расскажем, как решить проблемы, связанные с этим вопросом. В конце статьи приводятся некоторые операторы DDL для загрузки тестовых данных.
Запросы SELECT в MySQL
Запросы представляют собой процессы, состоящие из задач - их производительность непосредственно зависит от производительности каждой из этих задач.
Чтобы перейти к проблемам запросов SELECT, сначала необходимо понять, что происходит при выполнении этих запросов. Вот что делает MySQL за кадром, когда мы выполняем оператор SELECT:
- Наш SQL-клиент посылает запрос на сервер для выполнения.
- Выполняется конкретный план запроса.
- Возвращается результат.
Понимание этих шагов не менее важно, чем погружение в план выполнения запроса и вывод, обеспечиваемый выполнением оператора EXPLAIN - план выполнения запроса, даст нам информацию относительно времени, которое MySQL тратит на каждый шаг, необходимый для выполнения запроса. Оператор EXPLAIN обеспечит нас более подробной информацией о том, как MySQL выполняет сам запрос.
Для демонстрации мы будем использовать нижеприведенную таблицу с тремя столбцами (нет необходимости указывать движок хранилища - MySQL создаст таблицу на основе движка InnoDB по умолчанию, если не указать другой. В этом конкретном сценарии часть индексирования не обязательна, но т.к. она указана, MySQL создаст индекс с именем "email" (индексы могут иметь любые имена) на столбце с именем "email"). Отметим также размеры столбцов email и username - в данном случае электронные адреса не должны превышать 35 символов, а имена пользователей не могут быть длиннее 20.
Важно заметить, что для столбцов типа integer указание длины является устаревшим, начиная с MySQL 8. Таким образом, вы также можете оставить столбцы с целочисленным типом без указания атрибута длины:
CREATE TABLE demo_table (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(35) NOT NULL,
username VARCHAR(20) NOT NULL DEFAULT '',
INDEX email(email)
) ENGINE = InnoDB;Для вставки данных в таблицу используйте INSERT или LOAD DATA INFILE – INSERT является лучшим выбором, если вы имеете дело с небольшими наборами данных (менее 100 миллионов строк), а LOAD DATA INFILE может быть весьма полезен для работы с большими наборами данных. Для INSERT синтаксис выглядит так:
--Несколько строк для демонстрации. В конце статьи
--есть метод для загрузки большого числа строк.
INSERT INTO demo_table (email,username)
VALUES ('demo@demo.com', 'Demo'),
('demo2@demo.com', 'Demo'),
('Another@Email.com', 'AnotherDemo');Для LOAD DATA INFILE синтаксис включает FIELDS TERMINATED BY. Эта часть запроса может использоваться для указания символа, который разделяет поля (при желании можно также указать, в какие столбцы загружать данные, указав их в конце запроса):
LOAD DATA INFILE '/path/to/file.txt'
INTO TABLE demo_table [FIELDS TERMINATED BY '|'];План выполнения запроса
Чтобы глубже погрузиться в план выполнения запроса, мы можем использовать профайлер запросов MySQL или углубиться в более богатую схему производительности, выполнив шаги, описанные в документации MySQL. Поскольку для многих использование схемы запроса является более трудным, я буду использовать профайлер:
- Выберите базу данных, выполните затем команду SET profiling = 1, чтобы включить профилирование.
- Выполните ваш запрос, а затем команду SHOW PROFILES, чтобы исследовать все профили всех запросов.
- Выберите ID запроса, который вы только что выполнили (найдите запрос в списке, предоставленном профайлером), а затем выполните команду SHOW PROFILE FOR QUERY [id].
Замечание: профилирование запросов с помощью SET profiling = 1 считается устаревшим после версии MySQL 5.6.7, и предлагается вместо этого воспользоваться схемой производительности (следуйте документации по ссылке выше). Замечу лишь, что начать сразу использовать схему несколько сложнее, чем использовать профайлер.
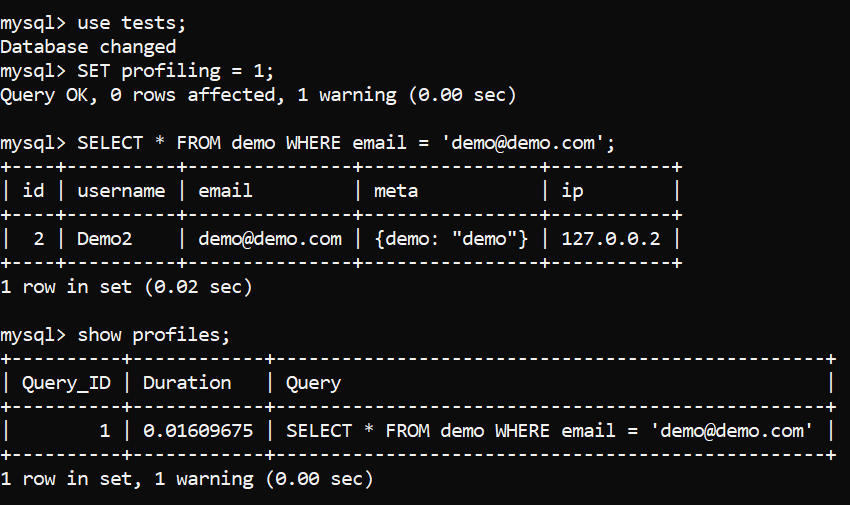
Рис.1 - Профилирование запроса. Инициализация
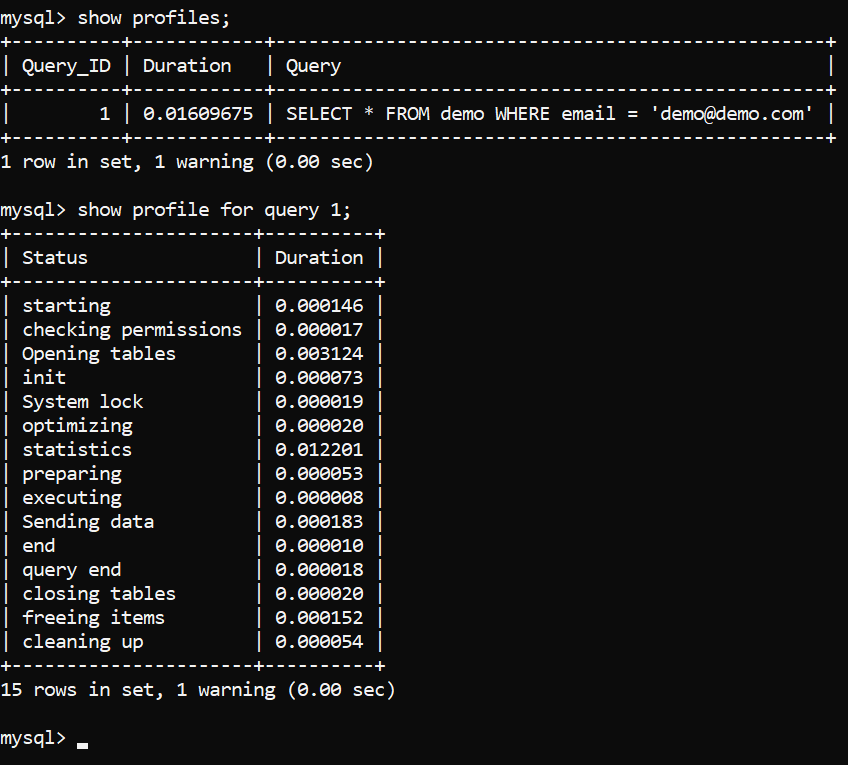
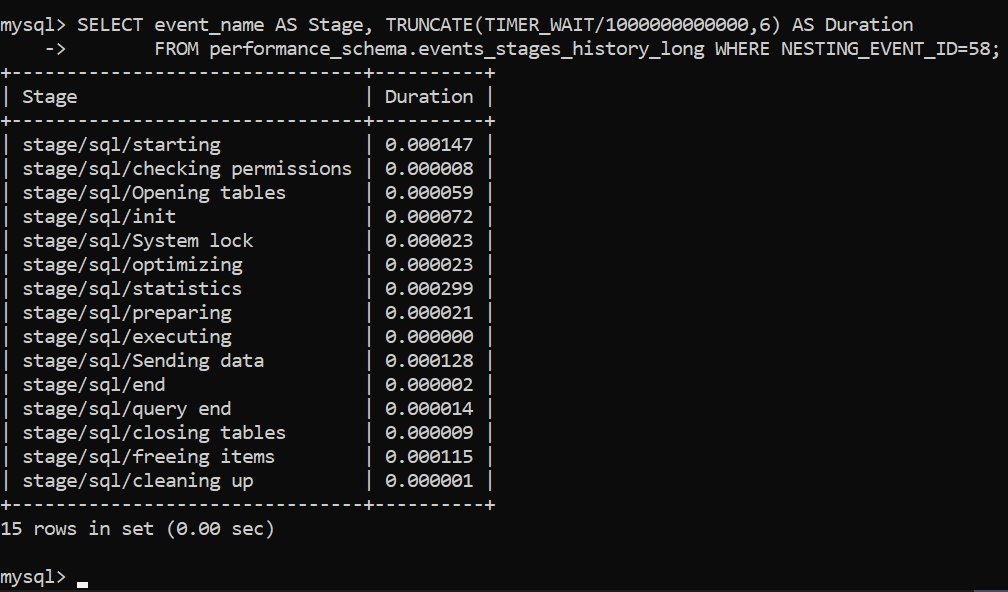
Рис.2 - Профилирование запроса. Результаты
План выполнения запроса показан выше. Теперь нам нужно правильно понять, что все это означает. Мы начнем сверху и будем двигаться вниз (для новых версий MySQL результаты будут немного отличаться - там может быть больше таких пунктов, как “Executing hook on transaction” и “waiting for handler commit”, но в целом все то же самое):
- Starting - процесс инициализации запроса.
- Checking permissions - относится к процессу проверки MySQL, что пользователь имеет достаточно прав для выполнения запроса. Если разрешения не предоставлены или их недостаточно, процесс на этом прерывается.
- Opening tables – процесс MySQL открывает все таблицы для работы. Как только таблицы открыты или они уже были открыты, MySQL переходит к шагу #4.
- Init – MySQL выполняет процессы инициализации, например, очищаются журнал InnoDB и двоичный журнал.
- System lock – как только MySQL достигает этой фазы, он ожидает снятия блокировки таблицы, если она имела место. На этой фазе запрос задействует функцию mysql_lock_tables() и ожидает ее завершения - более подробно об этом читайте в документации в параграфе “System lock”.
- Optimizing – внутренний процесс, выполняемый MySQL, для определения того, как выполнять запрос максимально быстрым способом. Представьте математическое уравнение - умножение 2 на 0 можно получить двумя способами: решением уравнения, или пониманием, что умножение на 0 всегда дает 0. Это то, что MySQL тут делает.
- Statistics – вычисление данных, связанных со статистикой для дальнейшей разработки плана выполнения запроса.
- Preparing - MySQL готовится к выполнению запроса.
- Executing – как только сервер достигает фазы выполнения, запрос выполняется, начиная производить выходные строки.
- Sending data – MySQL делает внутреннюю работу для выполнения запроса и возвращения результатов запроса.
- End – завершение запроса перед очисткой процесса.
- Query end – относится к завершению обработки запроса.
- Closing tables – закрываются таблицы, которые был открыты для выполнения запроса.
- Freeing items – означает, что MySQL освобождает элементы из потока, используемого для выполнения запроса.
- Cleaning up – наконец, эта стадия связана с очисткой всех элементов в памяти и сброс необходимых внутренних переменных.
Для тех, кто использует профайлер, результаты могут немного отличаться, но в целом совпадать. Чтобы применить профайлер, выполните следующее:
- Сказать MySQL включить мониторинг для пользователя, который выполняет запрос, с помощью двух запросов - первый для выключения мониторинга для всех, а второй включит мониторинг для указанного аккаунта (замените "root" на имя учетной записи):
UPDATE performance_schema.setup_actors SET ENABLED = 'NO', HISTORY = 'NO' WHERE HOST = '%' AND USER = '%';
INSERT INTO performance_schema.setup_actors (HOST,USER,ROLE,ENABLED,HISTORY) VALUES('localhost','root','%','YES','YES');

- Включить две вещи - журналы для операторов и этапов выполнения оператора, выполнив следующие запросы:
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE '%events_statements_%';
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE '%events_stages_%';
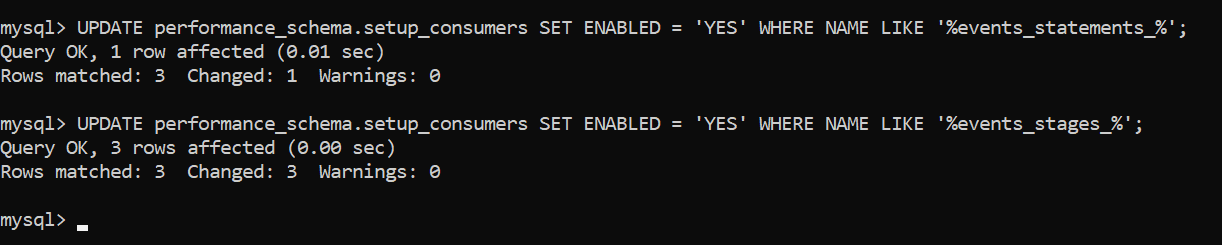
- Обновить таблицу setup_instruments с помощью таких запросов (у меня не будет совпадения, т.к. значения уже обновлены):
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES' WHERE NAME LIKE '%statement/%';
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES' WHERE NAME LIKE '%stage/%';

- Наконец, вы можете выполнить свой запрос:
SELECT * FROM demo WHERE email = 'demo@demo.com';
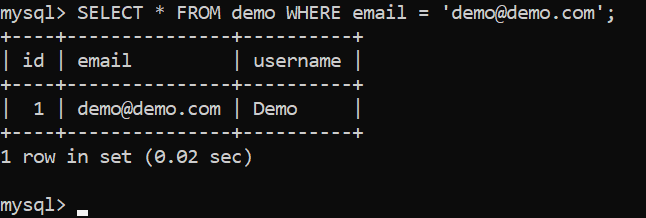
- Теперь найдем запрос, обратившись к истории запросов - выполните этот запрос (замените YOUR QUERY HERE текстом вашего запроса):
SELECT EVENT_ID, TRUNCATE(TIMER_WAIT/1000000000000,6) as Duration, SQL_TEXT FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like '%YOUR QUERY HERE%';
- Затем, чтобы увидеть продолжительность выполнения запроса и информацию об этапах, обратитесь к таблице истории запросов, например, так (замените Query_ID на ID вашего запроса):
SELECT event_name AS Stage,
TRUNCATE(TIMER_WAIT/1000000000000,6) AS Duration
FROM performance_schema.events_stages_history_long
WHERE NESTING_EVENT_ID = QUERY_ID;
Как видно, результаты не сильно отличаются, и раз мы в курсе, что означают задачи в плане выполнения запроса в контексте MySQL, мы можем начать оптимизировать их.
Оптимизация задач - запрос EXPLAIN
Чтобы оптимизировать задачи, которые составляют запрос SELECT, и в результате сделать запрос быстрее, нам нужно взглянуть на вывод оператора EXPLAIN, который объясняет, что делается с запросом внутри. Профилирование скажет нам, как долго выполняется каждый этап запроса, в то время как объяснение запросов расскажет нам, как фактически выполняется запрос. Напишем запрос SELECT как обычно, просто добавим в начале EXPLAIN. В качестве примера будем использовать следующий запрос:
EXPLAIN SELECT *
FROM demo_table
WHERE email = 'jfriesen@example.net';
Вывод оператора EXPLAIN сообщит нам следующие вещи:
- Столбец type говорит о том, как выполнялся доступ к строке (за более подробной информацией о различных методах доступа в запросе обратитесь к документации. SIMPLE в данном случае означает тот факт, что не был использован UNION или подзапрос).
- Столбец table скажет вам, на какой таблице выполнялся оператор SELECT. Для некоторых это может быть самоочевидно, но если вы выполняете множество операторов SELECT, такая возможность полезна. Документация содержит больше информации об этой функциональности.
- Столбец partitions сообщит, использовались ли секции, и, если так, их имена.
- Столбец possible_keys описывает индексы, которые MySQL мог бы выбрать. Столбец key показывает выбранный индекс, а столбец key_len выводит длину индекса на этом столбце. Обратите внимание, что длина ключа является длиной индекса, а не длиной данных (она не будет такой же, как определено типом данных.) В нашем случае длина индекса (длина ключа) также вычисляется MySQL, что дает значение "142". Больше информации о возможных индексах можно найти здесь, а о самих индексах - здесь.
- Столдец ref говорит нам, какие столбцы работали с индексом при выборке данных. Другими словами, MySQL ищет столбцы, которые работают с индексом, как описано в документации.
- Столбец rows показывает число строк в таблице. Имейте в виду, что для InnoDB это число приблизительное, являющееся оценкой, а не актуальным значением, поскольку InnoDB не хранит число строк, как это делает MyISAM.
- Столбец filtered показывает оценку числа строк, которое должно быть отфильтровано (т.е. не включаться в результирующй набор). Процентное отношение, представленное в этом столбце, является оценкой, поэтому не стоит удивляться, если вы увидите "100.00", как в примере выше.
- Имеются также другие возможные значения, например, значение select_type, которое описывает тип используемого оператора SELECT (было ли использовано предложение UNION т.п.).
Чтобы лучше понять результаты профилирования и оператора EXPLAIN, помните, что:
- Запрос SELECT будет тем быстрее, чем меньше он сканирует строк. Следовательно, мы должны избегать выборки всех столбцов в результирующий набор - достаточно выбрать только необходимые столбцы.
- Индексы (также называемые ключами)- это главная вещь для оптимизации производительности. Внимательно посмотрте на вывод оператора EXPLAIN - столбец “possible_keys” показывает индексы, которые MySQL может использовать, а столбец "key" - индекс, который был фактически выбран. Индексы делают запросы SELECT быстрее, поскольку при использовании индекса MySQL не читает все данные для нахождения значения столбца. Имеются разные типы индексов (мы поговорим об этом чуть позже), и индексы действительно заслуживают отдельной книги сами по себе (для лучшего понимания индексов обратитесь к ссылкам в конце статьи).
- Производительность запросов SELECT может быть также значительно улучшена при использовани секционирования. Секции выполняют внутреннее разбиение таблицы на несколько разных таблиц. Поскольку эти таблицы по-прежнему рассматриваются слоем хранения как одна таблица, они обычно хранят только данные, которые начинаются, скажем, с конкретного символа или числа. Тогда запрос использует данные в секции, а не во всей таблице, что делает его быстрее из-за обработки меньшего количества данных.
Индексы и секции - это две вещи, которые используются наиболее часто при оптимизации запросов SELECT - каждая из них имеет несколько типов сама по себе.
Как индексы, так и секционирование помогают оптимизировать производительность SELECT, поскольку индексы позволяют MySQL быстро находить строки по конкретным значениям в столбце, а секции действуют как таблицы внутри таблицы - MySQL может переключаться на них, когда запрос начинает поиск, начиная с конкретного символа, чтобы читать только строки таблицы, начинающеся с этого символа. Как результат, операторы SELECT оказываются более быстрыми в обоих случаях.
Типы индексов
Имеются такие типы индексов: B-Tree, R-Tree (пространственный) и хэш-индекс, при этом хэш-индексы поддерживаются только движком хранилища MEMORY:
- B-Tree: это наиболее часто используемый тип индекса. Эти индексы улучшают производительность запросов, которые ищут точное совпадене данных, используют операторы
"<" (меньше чем), ">" (больше чем) или операторы со знаком равенства (">=" и т.д.). Они также используются с подстановочными знаками, хотя не во всех случаях (мы познакомимся с ними чуть позже).
Индексы B-Tree представляют собой отсортированную деревовидную структуру, которая подходит для работы с множеством данных, благодаря своей способности обхода дерева сверху вниз в рекурсивной манере. В силу того, что индексы B-Tree отсортированы, поиск на точное совпадение (с использованием оператора "=") выполняется очень быстро. - Индексы R-Tree, или пространственные, используются при выполнении операций с географическими данным.
- Хэш-индексы используются для точного совпадения данных (т.е. для запросов, которые используют либо оператор "=", либо "<=>"), но только в рамках движка хранилища MEMORY.
Свойства индексов
У индексов также есть множество свойств, которые необходимо обсудить:
- Покрывающие индексы содержат все столбцы, необходимые для выполнения запроса; в этом случае MySQL может читать данные из индекса вместо обращения к таблицам. Поскольку чтение индекса выполняется значительно быстрей, чем чтение из соответствующих таблиц, запросы выполняются быстрее.
Тут все понятно: включите все столбцы, используемые запросом, в индекс, и вы получите покрывающий индекс. - Составные индексы иногда путают с покрывающими индексами, но это не одно и то же. Составные индексы имеют ключ, состоящий из нескольких столбцов, но эти столбцы не обязательно включают все столбцы, которые может использовать конкретный запрос.
- Префиксные индексы индексруют префикс (часть) столбца. Индексы такого типа часто используются разработчками с целью экономии места хранилища, но есть и другие преимущества. Например, если мы хотим проиндексировать первые 5 символов, имеющихся в столбце email, мы можем сделать это так:
CREATE INDEX prefix_idx ON demo_table(email(5));
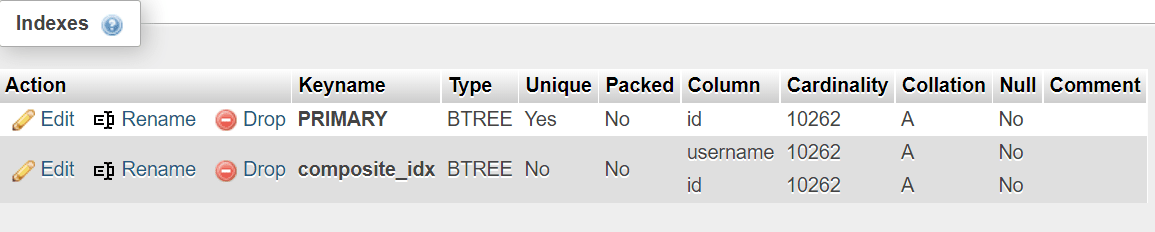
После создания такого индекса мы можем наблюдать в структуре таблицы в phpMyAdmin строку, содержащую "столбец (число символов)", это говорит о том, что индексируется только указанное число символов. Согласно MySQL, при большем количестве символов, чем определено, индекс используется для исключения строк, которые не отвечают запросу, а остальные строки сканируются для возможных вариантов использования с индексом (см. пример ниже). На следующем изображении можно увидеть, что у нас имеется PRIMARY KEY на столбце id и два других индекса:

- Кластеризованные индексы. Эти индексы уникальны в двух аспектах, во-первых, поскольку только один кластеризованный индекс может существовать для таблицы. Кроме того, кластеризованный индекс имеет тот же порядок строк, как и в таблице. В MySQL такие индексы часто используются для поддержки ограничения PRIMARY KEY, хотя это не обязательно.
Примеры индексов
Теперь примеры. Заметим, что в выводе оператора EXPLAIN столбец cardinality показывает не число строк в столбце, а число в нем уникальных значений.
- Индексы B-Tree обычно определяются так (email_idx - это имя индекса, а email - имя столбца):
ALTER TABLE `demo_table` ADD INDEX email_idx(email);
Если мы не хотим использовать ALTER, можно создать индекс так (email_idx - имя ключа, ключи - это другое наименование индекса):
CREATE INDEX email_idx ON demo_table (email, другие столбцы, если нужны ...);

- R-Tree, или пространственные, индексы могут быть определены только на географических данных, т.е. столбцах, имеющих тип данных GEOMETRY. Индексы R-Tree подходят для индексирования географических данных благодаря своей природе: структура данных подходит для географических координат, но держите в голове, что запросы с LIKE не всегда могут использовать эти индексы, как это можно увидеть ниже:
ALTER TABLE имя_таблицы ADD SPATIAL INDEX(столбец);

- Чтобы индекс был покрывающим индексом для запроса, он должен включать все столбцы в таблице, которые использует конкретный запрос. Так, например, если запрос выглядит так: SELECT c1, c2 FROM demo_table WHERE c1 = 'A' AND c2 = 'B'; то покрывающй индекс мог бы выглядеть так (phpMyAdmin также покажет кардинальное число обоих индексных столбцов справа):
ALTER TABLE `demo_table` ADD INDEX covering_idx (email,username);

В этом случае MySQL выбрал для использования покрывающий индекс - размер индекса - 224 символа.
Покрывающий индекс включает все поля, необходимые для выполнения запроса (смотри пример ниже), но не обязательно конкретным образом, т.е. если изменить порядок столбцов, индекс все равно останется покрывающим. Если ваш запрос выглядит подобно этому, вы весьма вероятно получите выгоду от индекса на столбцах c1, c2 и с3:
SELECT * FROM demo_table WHERE c1 = 'Demo' AND c2 = 'Demo' AND c3 = 'demo@demo.com';
- Составные индексы включают несколько столбцов, но они не обязательно покрывают все столбцы некоторого заданного запроса. Если имеется три столбца - c1, c2 и c3, составным индексом был бы любой индекс, который содержит несколько столбцов. Так индекс может включать столбцы c1 и c2, он может индексировать столбцы c3 и c1, это может быть другая комбинация - но если индекс не содержит все столбцы, требуемые запросу для выполнения, он не будет покрывающим индексом. Составные индексы - это просто индексы, которые включают в себя несколько столбцов и они не являются чем-то уникальным, кроме того факта, что ключевые столбцы необходимо упорядочить так, чтобы наиболее важные сканировались в первую очередь.
В этом случае мы покрываем столбцы username и id следующим оператором:
ALTER TABLE 'demo_table' ADD INDEX covering_idx(username,id);
- Индексирование префикса столбца может потребоваться для экономии места хранилища - золотое правило гласит: чем меньше символов находится в префиксе, тем лучше для хранилища, но хуже для производительности из-за дополнительного сканирования строк, которыет частично соответствуют заданному критерию. Если у вас недостаток места в хранилище, но все же желательно повысить производительность, решить проблему поможет префиксный индекс. Определите префиксный индекс, например, так (в этом примере предполагается, что столбец наывается c1 и мы индексируем первые 5 символов столбца):
ALTER TABLE 'demo_table' ADD INDEX idx_name(c1(5));
При использовании таких индексов мы все же можем искать точное совпадение, что показано ниже (мы проиндексировали только первые 5 символов, но запрос все же использовал индекс):

- Индексы PRIMARY KEY обычно определяются при создании таблицы, и они могут автоматически инкрементироваться:
CREATE TABLE demo_table (
'id' INT(255) PRIMARY KEY AUTO_INCREMENT,
`column_1` VARCHAR(255),
...
);
Как видно на изображении ниже, столбец id получал приращение 1 при вставке каждой строки в таблицу:
Что касается индексов ограничения PRIMARY KEY, имейте в виду, что тип столбца, который является первичным ключом, не обязательно должен быть целочисленным. Для MySQL ограничения PRIMARY KEY удовлетворяют следующим требованиям:
- Столбец, который имеет ограничение первичного ключа, не может допускать NULL-значения или пустые строки.
- Столбец, который имеет ограничение первичного ключа, должен содержать только уникальные значения.
- Таблица может иметь только одно ограничение первичного ключа.
- Длина столбца, который имеет ограничения первичного ключа, не может превышать 767 байтов.
Также имейте в виду, что ограничения первичного ключа могут состоять из нескольких столбцов - это может выглядеть так (обратите внимание на ограничение в строке 6):
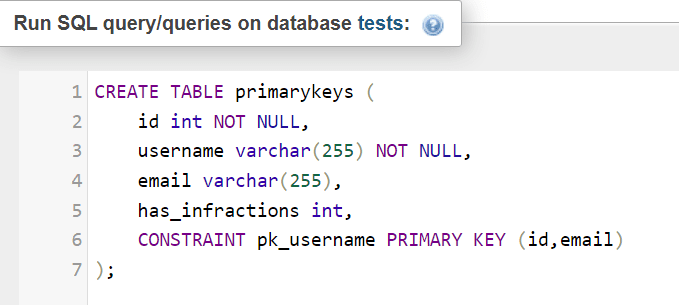
Индексы влияют на запросы разными способами: индексы B-Tree призваны помочь базе данных найти довольно быстро строки, удовлетворяющие конкретному предложению WHERE. Насколько может быть улучшена производительность, зависит от того, как настроены наши экземпляры. Некоторые индексы обычно добавляются при создании таблицы или с помощью оператора ALTER TABLE.
Имеются еще полнотекстовые индексы для тех, кто по большей части выполняет запросы, которые ведут себя подобно поисковому движку, например, при поиске в больших текстовых столбцах. Полнотекстовые индексы определяются добавлением ключевого слова FULLTEXT в операторах ALTER TABLE или CREATE TABLE, или при создании таблиц, например:
CREATE TABLE demo_table (
id INT(10) NOT NULL AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(35) NOT NULL,
username VARCHAR(20) NOT NULL DEFAULT '',
FULLTEXT KEY(email)
) ENGINE = InnoDB;Имеется также тип индекса, который подходит для движка хранилища MEMORY - хэш-индексы; их можно определить так (в этом случае demo_table_memory основана на движке хранилища MEMORY, а не InnoDB. Перед выполнением запроса проверьте это):
ALTER TABLE `demo_table_memory` ADD INDEX idx_name(column) USING HASH;Хэш-индексы поддерживаются, только когда используется движок хранилища MEMORY, и только на точное совпадение данных (критерии поиска с оператором "="). Заметим также, что вам следует иметь в виду количество доступной памяти сервера, чтобы не столкнуться с ошибкой “The table is full” (таблица заполнена; имя таблицы будет выглядеть странно, т.к. она находится в памяти):

Секционирование в MySQL
Здесь тоже есть несколько типов - помимо того, что таблицы могут быть секционированы горизонтально либо вертикально, имеется шесть типов секционирования. Также имейте в виду, что поскольку некоторые движки хранилища не поддерживают секционирования, секции рекомендуется использовать для движков хранилища InnoDB или XtraDB.
MySQL имеет шесть типов секционирования (на момент написания статьи MySQL поддерживал горизонтальное, но не вертикальное секционирование):
- Секционирование по диапазону (RANGE) - этот тип секционирования используется для разбиения данных, которые попадают в заданный диапазон. Например, если у нас большой набор данных и мы разыскиваем значения, начинающиеся с чисел, можно получить выигрыш от секций, которые начинаются с 0, 1, 2 и других чисел.
- Секционирование по списку (LIST) - этот тип секционирования используется для разбиения данных, при котором данные каждой категории попадают в отдельную секцию. Представьте географические данные, разбитые на Восток, Запад, Север или Юг. Такой тип секционирования будет полезен, когда используется 4 секции, и значения строк могут попадать в один или несколько определенных списков.
- Секционирование по столбцам (COLUMNS) позволяет выполнить разбиение, при котором несколько столбцов используется в качестве ключа секционирования.
- Секционирование по хэшу (HASH) часто используется при разбиени столбцов id. Этот тип секционирования позволяет разбить данные на заданное число секций с равным числом строк в каждой из них.
- Секционирование по ключу (KEY) подобно секционированию по хэшу, за тем исключением, что MySQL выбирает способ секционирования данных. Если такой способ не устраивает, не следует определять столбцы - достаточно просто задать число секций.
В списке ниже указывается, когда следует использовать тот или иной тип секционирования:
- Секционирование по диапазону часто используется поисковым движком, который имеет дело с большим объемом данных и необходим быстрый ответ на запросы SELECT.
- Секционирование по списку используется, когда нам нужна пара списков, попадающих в категорию.
- Секционирование по столбцам используется MySQL для определения секции, которую следует проверять на совпадение строк, или с целью размещения строк в секциях.
- Секционирование по хэшу гарантирует равномерное распределение данных по секциям.
- Секционирование по ключу подобно разбиению по хэшу, просто оно использует функцию хэширования, предоставленную MySQL.
Имеется также концепция, известная как субсекционирование; она относится к секциям внутри секций.
Секции обычно определяются при создании таблиц, например, так (в этом примере мы используем секционирование по ключу (KEY), но и другие типы секционирования могут быть определены в аналогичной манере. Обратитесь к документации и выполните эксперименты, прежде чем выбрать конкретный тип секционирования):
CREATE TABLE demo_table (
id INT NOT NULL PRIMARY KEY,
email VARCHAR(35) NOT NULL,
username VARCHAR(20) NOT NULL DEFAULT ‘’
) PARTITION BY KEY() PARTITIONS 5;В более новых версиях MySQL (MySQL 8.0 и выше - на момент написания этой статьи последней стабильной версией была MySQL 8.0.31) секционирование поддерживается только в движках хранилища InnoDB и NDB. При использовании более старых версий пользователи могут также выбрать секционирование в MyISAM. Более подробно о влиянии секционирования на выполнение операторов SELECT можно прочтать в документации.
Советы и приемы оптимизации операций чтения
Оптимизация операторов SELECT, использующая индексы, не является вполне беззаботной операцией, когда вы просто добавляете пучок индексов, и все работает. Проблемы являются неизбежной частью процесса оптимизации, поэтому мы также подготовили краткую шпаргалку с советами и рекомендациями, в которую вы можете заглядывать и решить, если не все, то, по крайней мере, большую часть возникших у вас проблем:
- Используйте где это возможно нормализацию - правильная нормализация базы данных обычно хорошо сказывается на запросах SELECT. Это вызвано отсутствием избыточных чтений данных. Имеются ограничения на основе емкости экземпляра, числе строк и количестве таблиц, которые задействует запрос, но почти всегда лучше иметь хорошо нормализованную базу данных.
- После создания индекса убедитесь, что ваши запросы используют индексы, которые вы создали для запросов, читающх данные. Используйте EXPLAIN, чтобы MySQL сообщил вам, какие индексы используются и почему (смотрите примеры выше), и корректируйте их при необходимости.
- Где необходимо, используйте предложение LIMIT и избегайте использования оператора "SELECT *", если это возможно - чем меньше данных вы выбираете, тем быстрей станут ваш запросы (значение по умолчанию для MySQL на ограничение числа столбцов - 200).
- Если возможно, избегайте чрезмерного усложнения ваших операторов SELECT. Иногда использование слишком большого числа выражений OR может заставить MySQL использовать индекс неоднократно. Имеет смысл рассмотреть вариант разбиения запроса на два запроса, возвращающих меньше строк (используйте LIMIT) или выбирающих меньше столбцов (вместо использования SELECT * используйте SELECT columnname, columnname2 и т.д.).
- Если вы используете подстановочные знаки с выражением LIKE (например, '%'), проверьте, чтобы он находился только в конце поисковой строки. Использование '%' в начале вашего выражения приведет к сканированию всех данных, что обычно замедляет поиск.
Запросы SELECT: DDL и данные
Как было обещано в начале статьи, теперь мы дадим пару операторов DDL, чтобы помочь вам начать.
Сначала мы должны создать таблицы (имена таблиц и их содержимое могут быть любыми - заметим также, что таблицы должны использовать движок хранилища InnoDB или XtraDB для достижения наилучших результатов в плане оптимизации):
CREATE TABLE demo_table (
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(35) NOT NULL,
username VARCHAR(20) NOT NULL DEFAULT ''
) ENGINE = InnoDB;- Теперь мы должны наполнить таблицу данными. Одним из методов решения этой задачи является использование генератора фиктивных данных FillDB - вставьте вашу схему базы данных (вам может потребоваться переименовать накоторые из ваших таблиц - генератор данных сохраняет все ранее использовавшиеся имена таблиц), затем сгенерируйте данные для столбцов:
- Наконец, укажите число генерируемых строк (мы рекомендуем генерировать не более 100000 строк за один раз, чтобы не перегружать ваш браузер), затем двигайтесь дальше:
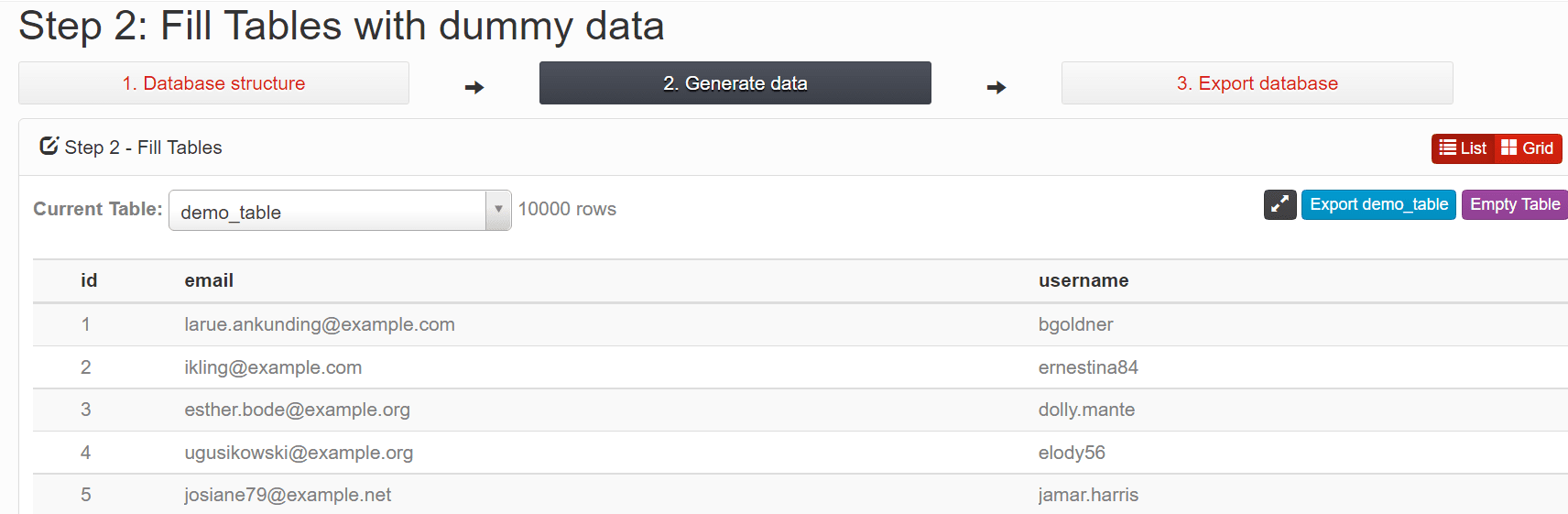
- Теперь ваши данные должны быть готовы - вы сможете просмотреть данные, которые были сгенерированы:
- Осталось только импортировать данные в свой экземпляр базы данных. Экспортируйте файл из генератора фиктивных данных, выполнив щелчок на голубой кнопке справа, на которой написано “Export tablename”.

Теперь импортируйте данные в MySQL, используя интерфейс командной строки или функциональность phpMyAdmin, и вы можете получить удовольствие от оптимизации своих запросов!
Недостатки оптимизации операторов SELECT
В конечном итоге, почти все, что нам необходимо сделать для оптимизации запроса SELECT, исходит из того факта, что нам требуется добиться того, чтобы MySQL смог получить доступ к как можно меньшему объему данных. Если это не помогает, обратитесь к конфигурированию экземпляра MySQL.
Однако одной из наиболее важных особенностей здесь является то, что при оптимизации запросов SELECT нам необходимо найти компромисс между хранением и производительностью запросов другого типа.
Это обусловлено тем, что индексы и секционирование ускоряют операции чтения, но замедляют запросы INSERT, UPDATE и DELETE, поскольку при модификации данных также необходимо выполнять параллельно операции вставки, обновления или удаления над индексами и секциями, и данные, возможно, также придется переносить внутри. Редко случается так, что вы имеете настолько много индексов, что это заметно вредит производительности, но все же случается, особенно для высоконагруженных приложений баз данных.
Следует также иметь в виду, что полезность индексов зависит во многом от того, насколько часто выполняются ваш запросы. Если запрос выполняется ежедневно и длится 10 секунд, стоит ли он всего того обслуживания, которое требует? Прежде чем применять любые советы, данные в этой статье, в производственной среде, проведите эксперименты и проверьте данные советы.
Заключение
Здесь были рассмотрены многие способы, которые помогут, как новичкам, так опытным администраторам баз данных оптимизировать производительность запросов SELECT в MySQL. Мы объяснили, что такое профилирование и как оно связано с прозводительностью, прошлись по плану выполнения, получаемому с помощью команды EXPLAIN, типам индексов и секционированию.
Ссылки по теме
1. Нюансы индексов в MySQL
2. Как секционировать таблицы MySQL
3. Проектирование индекса в базах данных и оптимизация: некоторые рекомендации
4. Понимание CRUD-операций на таблицах с индексами B-Tree, разбиение страниц и фрагментация
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой