
Оптимизация MySQL: добавление данных в таблицы
Пересказ статьи Lukas Vileikis. Optimizing MySQL: Adding Data to Tables
Добро пожаловать снова в серию статей по оптимизации MySQL! В том случае, если вы не следили за этой серией, ранее была опубликована пара статей, где обсуждались основы оптимизации запросов, а также оптимизация запросов на выборку (SELECT).
Здесь мы продолжим изучать способы оптимизации операторов INSERT и рассмотрим альтернативы, когда вам необходимо загрузить больше чем несколько строк в операторе LOAD DATA INFILE.
Как работает INSERT?
Как говорит название, INSERT является запросом, который используется для создания данных в таблицах базы данных. Внутреннее функционирование запроса INSERT в целом во многом идентично поведению оператора SELECT, что следует из предыдущей статьи, во-первых, база данных проверяет разрешения, открывает таблицы, инициализирует операции, проверяет необходимость блокировок строк, вставляет данные (обновляет индексы), после чего завершает выполнение.
Мы можем отследить это выполнив некоторое профилирование:
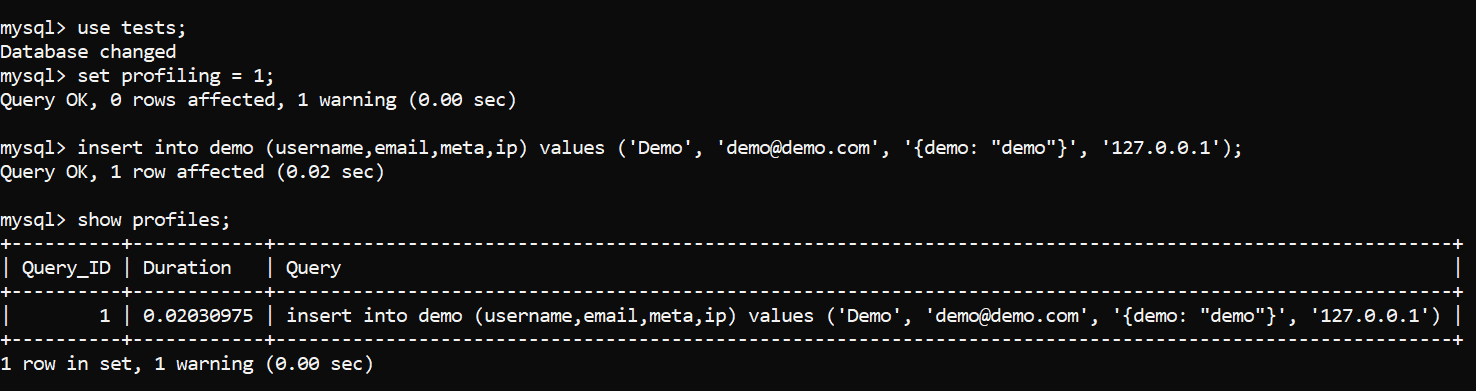
Рисунок 1 - профилирование запроса INSERT - запрос
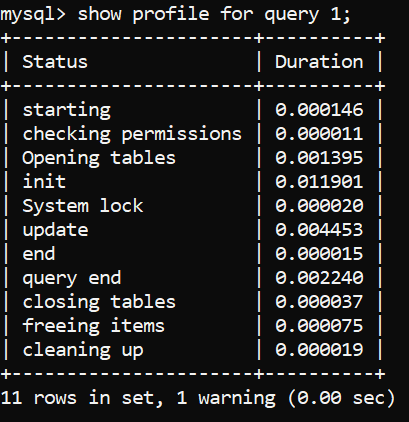
Рисунок 2 - профилирование запроса INSERT - состояние и длительность
Чтобы узнать, что означают эти коды состояния, обратитесь, пожалуйста, к предыдущей статье, где они объяснялись в отношении запросов SELECT; вкратце, представленные выше коды профилирования позволяют MySQL выяснить, среди прочего, следующие вещи:
- Были ли установлены соответствующие привилегии.
- Готовы ли таблицы для выполнения с ними неких операций (т.е. заблокированы они или нет).
- Как наилучшим образом выполнить операцию INSERT. Этот шаг включает*:
- Передачу запроса на сервер.
- Парсинг запроса.
- Сканирование таблицы для каких-либо индексов или секций
- Вставка строк в таблицы.
- Добавление данных в соответствующие индексы.
- Завершение процесса.
*Обратите внимание, что каждый шаг занимает часть общего времени на выполнение оператора INSERT. Согласно документации MySQL, самый быстрый процесс - это закрытие запроса, следующий за ним - передача запроса на сервер и его парсинг, а самый медленный - добавление данных в таблицу. (Заметим, что для очень небольшого количества данных, соединение с сервером может быть относительно затратным).
Что касается профилирования, оно действительно полезно при выполнении операций чтения, но не так сильно в других случаях: знание того, как запросы работают, полезно, но при оптимизации запросов INSERT, профилирование дает нам не так много, поэтому нам необходимо применять другие методы, с которыми мы скоро познакомимся.
Хочу еще напомнить, что неважно, какая система управления базами данных используется (INNODB и т.п.), многие запросы проходят одни и те же шаги - запросы INSERT также выполняют многие шаги, присущие запросам SELECT, однако, хотя имеется много общих шагов, важно помнить, что все запросы различаются по своей сути - запрос INSERT отличается от запроса SELECT в том, что запросы SELECT получают преимущество от индексов и секционирования, в то время как это в основном делает запросы INSERT медленнее.
Опытные администраторы БД знают, что запросы INSERT иногда используются совместно с запросами SELECT - мы начнем с базовых приемов, которые помогут нам улучшить производительность запроса INSERT, с последующим переходом к более сложным сценариям.
Базовые способы улучшить производительность запросов INSERT
Чтобы улучшить производительность запросов INSERT, начнем с профилирования запросов, затем удалим индексы или секции на таблице, если потребуется. Все индексы и секции замедляют запросы INSERT по одной простой причине - всякий раз при вставке в таблицу все индексы и секции таблицы должны обновляться, чтобы база данных знала, куда помещается строка. Справедливо то, что не важно, какой тип секционирования используется или какие индексы имеются - чем больше индексов или секций имеется у таблицы, тем медленнее будет становиться ваш запрос.
Замечание. Помните, что настройка производительности должна рассматриваться как целостная деятельность, и мы фокусируемся на настройке операторов INSERT только здесь. Индексы необходимы для большинства ваших операторов SQL, и если вы не добавляете много данных в таблицу, то обычно нежелательно удалять их только для того, чтобы сделать конкретные операции INSERT немного быстрее (тем самым убивая производительность чтения).
Другой очень популярный и простой способ улучшить производительность запроса состоит в объединении небольших операций в одну операцию большего размера. Мы можем также заблокировать таблицы и снять блокировки только тогда, когда все операции будут завершены; и эти подходы выглядят так:

Рисунок 3 - типичный способ улучшить производительность запроса INSERT
Итак, для оптимизации скорости выполнения запросов INSERT, мы должны придерживаться следующей магии: вместо многих запросов, каждый из которых вставляет пару строк, следует выполнить один большой запрос, который вставляет много строк сразу, после того как таблица заблокирована; обновление индексов и проверки согласованности по возможности откладываются (в идеале отложите эти процессы до конца выполнения запроса).
Когда это возможно, задержка всех этих вещей не является сложной и может быть выполнена, следуя некоторым или всем из этих шагов. Рассмотрите возможность выполнения этих шагов, если вы работаете с более чем миллионом строк и (или) когда вы видите, что ваши запросы INSERT могут быть объединены в единую операцию, как в примере выше (необязательно следовать этим шагам сверху донизу - один или два шага обычно будут хороши для начала):
- Заблокируйте таблицы перед вставкой в них данных, снимайте блокировки, как только все данные будут вставлены, но не раньше (см. пример выше). При блокировке таблиц данные в них не будут изменяться (параллельными транзакциями), пока данные не будут вставлены.
- Начните транзакцию (START TRANSACTION) перед выполнением запросов INSERT - по завершению выполните оператор COMMIT.
- Избегайте добавления каких-либо индексов перед операциями вставки, пока они не будут завершены.
- Если возможно, убедитесь, что таблица, в которую вы вставляете данные, не секционирована, поскольку секционирование разбивает вашу таблицу на несколько подтаблиц, и при вставке данных MySQL должен выполнить пару дополнительных шагов, чтобы выяснить, в какую секцию какие данные вставлять и т.п. Хотя правильное использование секционирования помогает улучшить производительность операторов SELECT, секционированные таблицы будут неизбежно занимать немного больше места на диске, так что будьте осторожны с этим.
Следуйте этим шагам, и вы будете на правильном пути выполнения операторов INSERT! Однако следует заметить, что это только основы, и такой подход может не подойти к вашему сценарию - в этом случае нам может потребоваться выполнить некоторую дополнительную оптимизацию за счет выделения количества потоков ввода-вывода в InnoDB путем изменения my.cnf (обратитесь к опциям на скриншоте ниже), или улучшить производительность запроса путем выполнения других действий, о которых вы узнаете в этой статье. Продолжайте читать - и ваш запросы INSERT скоро будут летать!
Продвинутое улучшение производительности запросов INSERT
Если вы уверены, что все ваши запросы INSERT профилированы и делают то, что вы ожидали, примените базовые шаги, описанные выше для улучшения их производительности. Если это не помогает, рассмотрите следующие советы:
- Мы можем начать явную транзакцию с помощью START TRANSACTION или, выполнив autocommit=0, выполнить все наши запросы INSERT, затем выполнить оператор COMMIT. При этом мы откладываем фиксацию транзакции до тех пор, пока не будет завершен последний запрос INSERT - в этом случае MySQL экономит время, поскольку он не фиксирует (commit) каждый выполненный оператор SQL, а фиксирует сразу все после. Чем больше набор данных, тем больше экономия времени.
Такой подход не очень подходит для миллиардов строк (запросы INSERT не предназначены для более чем 50 или 100 миллионов строк одновременно - иногда это зависит от используемого железа - нам потребуется использовать для этого LOAD DATA, поскольку операторы INSERT приведут к большим накладным расходам - подробнее об этом позже). Но если мы не имеем дела с таким большим числом строк, то это определенно может подойти. - Мы можем модифицировать файл my.cnf и добавить или изменить следующие опции, чтобы увеличить возможности ввода/вывода InnoDB (главный движок хранилища в MySQL):

Рисунок 4 - увеличение возможности ввода/вывода InnoDB
- Опция innodb_read_io_threads устанавливает число потоков для обработки операций чтения - в большинстве случаев значения 32 достаточно и следует оставить значение по умолчанию.
- Опция innodb_write_io_threads устанавливает число потоков для обработки операций записи - в большинстве случаев значения 32 также достаточно и следует оставить значение по умолчанию.
- Опция innodb_io_capacity определяет общую способность ввода/вывода InnoDB и это значение следует установить в максимальное значение IOPS, доступное для сервера. Это главным образом относится к потокам, которые выполняют различные связанные с базами данных задачи в фоновом режиме (работа с буферным пулом, запись изменений и т.д.) - в то же время эти потоки стараются не оказывать отрицательного воздействия на InnoDB. Более подробную информацию об этом можно найти в документации MySQL.
- Я опубликовал ранее статью относительно оптимизации my.cnf для общей производительности, где даются подробности настроек.
- Мы можем вставить больше данных сразу при помощи операции массовой вставки, доступной в рамках самого оператора INSERT. При использовании этого подхода мы можем избежать определения столбцов, в которые мы загружаем данные, если мы загружаем все данные сразу. Обратите внимание, что если мы решим игнорировать столбцы и у нас имеется столбец AUTO_INCREMENT, мы должны указать значение NULL (ниже приведен пример).

Рисунок 5 - пример оператора INSERT INTO
Дополнительные возможности для повышения производительности INSERT
Предыдущие шаги помогут вам оптимизировать ваши запросы INSERT; однако это только основы. Опытные администраторы БД знают пару дополнительных способов улучшить производительность запросов INSERT и некоторые профессиональные советы, включая сочетание операторов операторов INSERT c операторами SELECT!
Блокировки и конкурентная вставка строк
Многие из вас знают, что выполнение операторов INSERT означает блокировки для InnoDB: MySQL работает с каждым оператором отдельно и, поскольку речь идет об операторах INSERT, наложение блокировок InnoDB на уровне строк имеют преимущества для конечного пользователя: движок хранилища устанавливает блокировку на вставляемую строку, не оказывая тем самым влияния на любые операции с любыми другими строками в той же таблице. Пользователи могут по-прежнему работать со своими таблицами на базе InnoDB, в то время как они вставляют данные, пока необходимые им строки не блокируются, и они не накладывают блокировку на всю таблицу.
Перед вставкой любой строки MySQL также дает InnoDB знать, что строка будет вставляться с установкой эксклюзивной блокировки на вставку. Назначение этой блокировки - дать знать другим транзакциям, что данные вставляются в определенное место, чтобы другие транзакции не вставляли данные в то же самое место.
Чтобы наилучшим способом использовать блокировки InnoDB, следуйте совету выше - используйте операторы массовой вставки и рассмотрите возможность отложить все операции commit до окончания последнего запроса INSERT: массовые операторы INSERT будут вставлять данные более быстрым способом, а фиксация операции только после последнего запроса также ускорит процедуру.
Вставка строк из запроса SELECT
Как отмечалось выше, запросы INSERT являются главным способом вставки данных в MySQL, однако многие администраторы знают, что запросы INSERT не всегда так просты: в определенных ситуациях может потребоваться использовать их в сочетании с другими - обычно операторами SELECT. Подобный запрос отработает вполне успешно:
INSERT INTO table_name (FirstColumnName, SecondColumnName)
SELECT FirstColumnName, SecondColumnName
FROM another_table [options]Например:

Рисунок 6 - совместное использование запросов INSERT и SELECT
Заметим, что в этом случае индексы не будут полезны в таблице, где создаются новые строки, но полезны для извлечения строк из таблицы в операторе SELECT. Заметьте, что в образце запроса another_table может ссылаться на ту же самую таблицу, например, так:
INSERT INTO table_name (FirstColumnName, SecondColumnName)
SELECT FirstColumnName, SecondColumnName
FROM table_name [options]В связи с этим индексы могут оказаться (в зависимости от предложения WHERE в запросе) как полезны, так и вредны в одно и то же время.
Запрос CREATE TABLE … SELECT
Для выборки данных непосредственно в новую таблицу мы можем также применить оператор CREATE TABLE совместно с запросом SELECT. Другими словами, мы можем создать таблицу и вставить в нее данные без выполнения последующего отдельного оператора INSERT. Имеется два способа сделать это:
- Выполнить оператор CREATE TABLE с оператором SELECT без определения столбцов или типов данных:
CREATE TABLE new_table [AS] SELECT [columns] FROM old_table;
MySQL воссоздаст все столбцы, типы данных и данные из old_table. - Вы можете также определить столбцы и ограничения и вставить данные в новую таблицу таким образом:
CREATE TABLE new_table (
column1 VARCHAR(5) NOT NULL,
column2 VARCHAR(200) NOT NULL DEFAULT ‘None’
) ENGINE = InnoDB
SELECT demo_column1, demo_column2
FROM old_table;
Выборка данных из одной таблицы для вставки непосредственно в другую таблицу обычно происходит быстрее, чем INSERT INTO ... SELECT.
Лучший способ для массовой загрузки наборов данных - INSERT или LOAD DATA INFILE
LOAD DATA INFILE является встроенной функцией для быстрой вставки данных из текстовых файлов. Скорость достигается за счет игнорирования или устранения накладных расходов, которые присущи запросам INSERT, при этом:
- Работая с "чистыми" данными (данные разделяются только определенными разделителями (",", ":", "|" или вообще без разделителей).
- Предоставляя возможность загружать данные в конкретные столбцы или пропускать загрузку данных в определенные строки и/или столбцы.
Чтобы использовать LOAD DATA INFILE, убедитесь, что в вашем файле столбцы разделяются определенным разделителем (обычно разделителями является ",", символ TAB, пробелы, символы “|”, “:” и “-“) и предпочтительно, чтобы файл был в формате CSV или TXT. Сохраните файл в каталоге и запомните путь к нему, затем используйте следующий запрос (замените путь к файлу на ваш, а символ "|" на ваш разделитель
и demo_table на имя вашей таблицы) - используйте IGNORE, чтобы игнорировать все ошибки, допущенные запросом (проблема дубликатов ключа и т.д.):
LOAD DATA INFILE ‘/var/lib/mysql/tmp/data.csv’ [IGNORE]
INTO TABLE demo_table FIELDS TERMINATED BY ‘|’;Для экспорта данных из базы данных, чтобы иметь возможность последующего импорта с помощью запроса LOAD DATA INFILE, используйте запрос SELECT * INTO OUTFILE - примените IGNORE, если вы хотите проигнорировать все ошибки.
SELECT *
FROM demo_table [IGNORE]
INTO OUTFILE '/var/lib/mysql/tmp/data.csv'
FIELDS TERMINATED BY '|';LOAD DATA INFILE имеет много параметров, которые также могут использоваться. Эти параметры, среди прочих, включают:
- Параметр PARTITION позволяет определить секцию, в которую вы хотите вставить данные.
- Комбинируйте опцию IGNORE с опциями LINES или ROWS, чтобы сообщить MySQL сколько строк пропустить при вставке данных.
- Предоставление возможности установить значения определенных столбцов с помощью опции SET (запрос ниже берет данные из файла “demo.csv” с разделителем столбцов ":" и загружает их в таблицу с именем demo после пропуска 100 строк от начала, а также устанавливает столбец date в текущее значение даты, когда загружаются все строки):
LOAD DATA INFILE ‘demo.csv’ INTO TABLE demo
FIELDS TERMINATED BY ‘:’ IGNORE 100 LINES SET date=CURRENT_DATE();
LOAD DATA INFILE можно сделать даже более быстрым, если мы применяем ограничения DEFAULT. Если имеются столбцы, которые требуется заполнить одними и теми же данными в каждой строке, ограничение DEFAULT будет более быстрым, чем получение данных из потока. Таким образом, все столбцы, имеющие значения по умолчанию будут предварительно заполнены без необходимости загружать в них данные.
Такой подход очень удобен для экономии времени, когда один столбец содержит одинаковые данные и вы не хотите выполнять запросы ALTER (эти запросы создают копию таблицы на диске, вставляют в них данные, выполняют операции во вновь созданной таблице, а затем меняют эти таблицы). Вот пример:
CREATE A TABLE demo_table (
`demo_prefilled_column` VARCHAR(120) NOT NULL
DEFAULT 'Value Here',
) ENGINE = InnoDB;Чтобы глубже познакомиться с LOAD DATA INFILE, обратитесь к документации MySQL.
Индексы, секции и FAQ на INSERT
Даже если LOAD DATA INFILE не помогает, вам может быть захочется взглянуть на индексы и секции. Помните, о чем говорлось выше? Чем больше индексов или секций имет ваша таблица, тем медленнее будут ваши запросы INSERT. Вы уже знаете, что делать - но может быть стоит рассмотреть некоторые вопросы, часть из которых приводятся ниже:




Балансировка производительности INSERT и чтений
Чтобы сбалансировать производительность между запросами INSERT и SELECT, имейте в виду следующее:
- Основы помогают - выбирайте лишь те строки, которые необходимы, используя список столбцов в операторе SELECT вместо SELECT *, и индексируйте только те столбцы, по которым выполняется поиск.
- Нормализуйте таблицы - нормализация таблиц помогает экономить место в хранилище, а также увеличивает скорость запросов на чтение при правильном использовании. Выберите подходящий вам метод нормализации, а затем двигайтесь дальше.
Следует отметить, что, как и везде, нормализация может также иметь отрицательный эффект - больше таблиц и связей может означать больше отдельных операторов INSERT или LOAD DATA INFILE, но если все сделать правильно, ваша база данных должна крутиться быстро! - Используйте подходящий движок хранилища - это должно быть очевидно, но вы бы удивились, как много неопытных администраторов БД допускают ошибку при использовании неподходящего движка для своих задач. Если вы используете MySQL, то обычно применяются InnoDB или XtraDB.
Если вы работаете в тестовой среде и память не является проблемой, вариантом может также быть движок хранилища MEMORY, но имейте в виду, что этот движок хранилища не может быть так сильно оптимизирован, и что данные так или иначе не хранятся на диске - при этом запросы на вставку должны летать, но хранение самих данных в памяти означает, что выключение сервера разрушит все ваши данные. - Используйте мощный сервер - это идет рука об руку с оптимизацией my.cnf или других файлов. Если ваш сервер достаточно мощный, балансировка операций INSERT и SELECT будет легкой.
- Используйте только необходимые индексы и секции, не создавайте ничего лишнего - индексируйте только те столбцы, которые влияют на тяжелые запросы SELECT, и выполняйте секционирование таблиц, если в них более 50 миллионов записей.
- Рассмотрите возможность разбиения операторов INSERT - если вы должны импортировать огромные объемы данных, разбейте их на файлы, и загрузите эти файлы с помощью LOAD DATA INFILE.
Заключение
В этой статье мы рассмотрели пути наилучшей оптимизации запросов INSERT в целях повышения производительности и ответили на наиболее часто задаваемые вопросы, относящиеся к этому типу запросов. Мы также коснулись важности сбалансированного выполнения операций INSERT и SELECT, а также разбиения запросов INSERT при загрузке множества данных.
Некоторые из данных советов известны многим администраторам БД, хотя некоторые могут быть вообще неизвестны. Возьмите отсюда, что пожелаете - необязательно следовать пошагово всему, напсанному в этой статье. Сочетание некоторых из данных советов с советами из других частей этой серии благотворно скажется на вашей базе и приложениях.
Ссылки по теме
1. Проверочные ограничения (check)
2. Синтаксис MySQL CREATE TABLE для разработчиков T-SQL
3.
Как работает конфигурация MySQL?
4. Резервирование в MySQL: физические и логические резервные копии
5. Нормализация для сокращения блокировок
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой