
NULL в Oracle
Пересказ статьи Andrei Rogalenko. NULL in Oracle
Ключевые моменты
Специальное значение NULL означает отсутствие данных, утверждение того факта, что значение неизвестно. По умолчанию столбцы и переменные любого типа могут принимать это значение, если они не имеют ограничения NOT NULL. Помимо этого, СУБД автоматически добавляет ограничение NOT NULL для столбцов, входящих в первичный ключ таблицы.
Главная особенность NULL состоит в том, что оно ничему не равно, даже другому NULL. Вы не можете сравнивать с ним любое значение с помощью операторов: =, <, >, like ... Даже выражение NULL != NULL не будет истинным, поскольку нельзя однозначно сравнивать одно неизвестное значение с другим. К слову, это выражение не будет и ложным (false), т.к. при вычислении условий Oracle не ограничивается состояниями TRUE и FALSE. Благодаря наличию элемента неопределенности в виде NULL, имеется еще одно состояние - UNKNOWN.
Таким образом, Oracle оперирует не в двузначной, а в трехзначной логике. Эта особенность была положена Коддом в основание своей реляционной модели, и Oracle, являясь реляционной СУБД, полностью следует этим принципам. Чтобы не задумываться над «странными» результатами запросов, разработчику следует знать таблицу истинности трехзначной логики.
Для удобства создадим процедуру, которая печатает состояние булева параметра:
Привычные операторы сравнения пасуют перед NULL:
Имеются специальные операторы, IS NULL и IS NOT NULL, которые допускают сравнение с NULL. IS NULL будет возвращать true, если операнд NULL, и false - в противном случае.
Соответственно, IS NOT NULL работает наоборот: он вернет true, если значение операнда не-NULL, и false, если он равен NULL:
Дополнительно имеется пара исключений из правил относительно сравнений отсутствующих значений. Первое - это функция DECODE, которая считает два значения NULL эквивалентными друг другу. Во-вторых, составные индексы: если два ключа содержат пустые поля, но все их непустые поля равны, то Oracle рассматривает эти два ключа эквивалентными.
DECODE идет против системы:
Обычно состояние UNKNOWN обрабатывается так же, как FALSE. Например, если вы выбираете строки из таблицы, а условие x = NULL в предложении WHERE дает UNKNOWN, то вы не получите никаких строк. Однако есть одно отличие: если выражение NOT(FALSE) возвращает true, то NOT(UNKNOWN) возвращает UNKNOWN. Логические операторы AND и OR также имеют свои свои особенности при обработки состояния неизвестности. Конкретика - в примерах ниже.
В большинстве случаев результат unknown трактуется как FALSE:
Отрицание unknown дает unknown:
Оператор OR:
Оператор AND:
Давайте начнем с нескольких предварительных мероприятий. Для тестов создадим таблицу T с одним числовым столбцом A и четырьмя строками: 1, 2, 3 и NULL.
Включите трассировку запросов (для этого у вас должна быть роль PLUSTRACE).
В листинге трассировки оставлена только фильтрующая часть, чтобы показать, во что разворачиваются условия, указанные в запросе.
Прелюдия закончена. Теперь давайте поработаем с операторами. Попробуем выбрать все записи, которые включены в набор (1, 2, NULL):
Как можно увидеть, строка с NULL не была выбрана. Это связано с тем, что оценка предиката "A"=TO_NUMBER(NULL) вернула статус UNKNOWN. Для того, чтобы включить значения NULL в результаты запроса, вам нужно задать его явно:
Теперь попробуем с NOT IN:
Вообще ни одного результата! Давайте посмотрим, почему тройка не была включена в результаты запроса. Вручную вычислим фильтр, применяемый СУБД для случая A = 3:
В силу особенностей трехзначной логики, NOT IN вообще не дружит с NULL: как только NULL встречается в условиях отбора, не ждите никаких данных.
Здесь Oracle отходит от стандарта ANSO SQL и заявляет об эквивалентности NULL и пустой строки. Это, возможно, наиболее спорный момент, который время от времени поднимает многостраничные дискуссии с переходом на личности и другие непременные атрибуты жестких споров. Судя по документации, сам Oracle был бы не против изменить эту ситуацию (говоря, что хотя сейчас пустая строка трактуется как NULL, это может измениться в будущих релизах), но в настоящее время для этой СУБД написано такое огромное количество кода, что принять изменение поведения системы вряд ли реально. Более того, они начали говорить об этой по меньшей мере, начиная с седьмой версии (1992-1996), а сейчас на подходе двенадцатая.
NULL и пустая строка эквивалентны:
Если последовать завету классика и посмотреть в корень, то причина эквивалентности пустой строки и NULL может быть обнаружена в формате хранения varchar и NULL в блоках данных. Oracle хранит строки таблицы в структуре, состоящей из заголовка, за которым следуют столбцы данных. Каждый столбец представлен двумя полями: длиной данных в столбце (1 или 3 байта) и самими данными. Если varchar2 имеет нулевую длину, то в поле данных нечего записывать, это не занимает ни одного байта, и в поле длины записывается специальное значение 0xFF, означающее отсутствие данных. NULL представлен точно так же: поле данных отсутствует, а в поле длины записывается 0xFF. Разработчики Oracle могли бы, конечно, разделить эти два состояния, но так было у них с давних времен.
Конкретно для меня эквивалентность пустой строки и NULL кажется довольно естественным и логичным. Само имя "пустая строка" подразумевает отсутствие смысла, пустоту, дырку от бублика. NULL в целом означает то же самое. Но тут имеется неприятное последствие: Если мы можем с определенностью сказать, что пустая строка имеет нулевую длину, то о длине NULL так определенно не скажешь. Следовательно, выражение length('') будет возвращать NULL, а не нуль, как вы очевидно ожидали. Другая проблема: вы не можете сравнивать с пустой строкой. Выражение val = '' вернет состояние UNKNOWN, т.к. фактически это эквивалентно val = NULL.
Длина пустой строки является неопределенной:
Невозможно сравнение с пустой строкой:
Критики подхода Oracle утверждают, что пустая строка не обязательно означает "неизвестно". Например, менеджер по продажам заполняет карточку клиента. Он мог указать свой контактный номер (555-123456), мог указать, что он неизвестен (NULL), или мог указать, что контактного номера нет (пустая строка). При методе хранения пустых строк в Oracle будет проблематичным применить последний вариант. С точки зрения здравого смысла аргумент справедлив, но я всегда спрашиваю и не получаю четкого ответа: как менеджер будет вводить пустую строку в поле "phone", и как он будет в последующем отличать ее от NULL? Конечно, есть варианты, но все же...
На самом деле, если мы говорим о PL/SQL, то где-то глубоко внутри ядра пустая строка и NULL различаются. Это можно увидеть, поскольку ассоциативные коллекции позволяют вам сохранить элемент с индексом '' (пустая строка), но не позволяет сохранить элемент с индексом NULL:
Для того, чтобы избежать проблем, лучше уяснить для себя правило из документации: пустая строка и NULL неотличимы в Oracle.
Поведение конкатенации отличается: вы можете добавить NULL к строке, и это не изменит ее. Это политика двойных стандартов.
Почти все агрегатные функции, за исключением COUNT (и даже это не всегда), игнорируют NULL-значения при вычислениях. Если этого не делать, то первое же попавшееся значение NULL дало бы результату функции значение unknown. Возьмем для примера функцию SUM, с помощью которой необходимо просуммировать ряд (1, 3, null, 2). Если учитывать пустые значения, то мы должны получить следующую последовательность действий:
Вас вряд ли бы удовлетворило такое вычисление агрегатов.
Эта таблица с данными будет неоднократно использоваться ниже:
Пустые значения игнорируются агрегатами:
Функция COUNT подсчитывает строки; если используется COUNT(*) или COUNT(константа), NULL-значения будут учитываться. Однако если используется COUNT(выражение), то значения NULL будут игнорироваться.
С константой:
С выражением:
также следует быть осторожным с функцией AVG. Поскольку она игнорирует значения NULL, результатом для столбца N будет (1+3+2)/3, а не (1+3+2)/4. Возможно вам не подходит такое вычисление среднего значения. Для решения проблемы есть стандартное решение - использование функции NVL:
Агрегатные функции возвращают UNKNOWN, если они применяются к пустому набору данных или если набор данных содержит только значения NULL. Исключение составляют функции REGR_COUNT и COUNT(выражение), предназначенные для вычисления числа строк. Они вернут нуль в перечисленных выше случаях.
Набор данных, состояший только из NULL:
Пустой набор данных:
При создании индекса Oracle включает записи в индексные структуры для всех строк, содержащих значения NULL в индексируемом столбце. Такие записи называются NULL-записями. Это позволяет вам быстро идентифицировать строки, где соответствующий столбец содержит NULL, что может быть полезно при выполнении запросов с NULL и не-NULL условиями.
Важно помнить, что использование NULL в индексах может быть полезным, но не всегда. При создании индексов с NULL следует уделать внимание кардинальности NULL-значений в столбцах и их фактическому использованию в запросах. Это поможет избежать ненужных индексов и улучшить производительность базы данных.
При создании индлексов с NULL рекомендуется проанализировать производительность запросов и сравнить ее с производительностью без индексов. Это поможет вам определить индексы с NULL, которые действительно улучшают производительность и оправданы в вашей конкретной ситуации.
Следование этой практике позволит эффективно использовать NULL-значения в индексах Oracle, улучшить производительность запросов и уменьшить воздействие на систему. Широкое использование NULL-индексов поможет вам получить максимум от использования индексов и повысит эффективность базы данных.
Ссылки по теме
1. Трехзначная логика и предложение Where
2. Столбцы, допускающие NULL-значения, и производительность
3. Правильный способ проверки на NULL в запросах SQL Server
4. Соединение таблиц в SQL Server, когда столбцы включают NULL-значения
5. Агрегатные функции
6. Агрегатная функция от агрегатной функции
Для удобства создадим процедуру, которая печатает состояние булева параметра:
procedure testBool( p_bool in boolean ) is
begin
if p_bool = true then
dbms_output.put_line('TRUE');
elsif p_bool = false then
dbms_output.put_line('FALSE');
else
dbms_output.put_line('UNKNOWN');
end if;
end;Привычные операторы сравнения пасуют перед NULL:
exec testBool( null = null ); -- UNKNOWN
exec testBool( null != null ); -- UNKNOWN
exec testBool( null = 'a' ); -- UNKNOWN
exec testBool( null != 'a' ); -- UNKNOWNСравнение с NULL
Имеются специальные операторы, IS NULL и IS NOT NULL, которые допускают сравнение с NULL. IS NULL будет возвращать true, если операнд NULL, и false - в противном случае.
select case when null is null then 'YES' else 'NO' end from dual; -- YES
select case when 'a' is null then 'YES' else 'NO' end from dual; -- NOСоответственно, IS NOT NULL работает наоборот: он вернет true, если значение операнда не-NULL, и false, если он равен NULL:
select case when 'a' is NOT null then 'YES' else 'NO' end from dual; -- YES
select case when null is NOT null then 'YES' else 'NO' end from dual; -- NO
Дополнительно имеется пара исключений из правил относительно сравнений отсутствующих значений. Первое - это функция DECODE, которая считает два значения NULL эквивалентными друг другу. Во-вторых, составные индексы: если два ключа содержат пустые поля, но все их непустые поля равны, то Oracle рассматривает эти два ключа эквивалентными.
DECODE идет против системы:
select decode( null
, 1, 'ONE'
, null, 'EMPTY' -- это условие будет истинным
, 'DEFAULT'
)
from dual;Логические операции и NULL
Обычно состояние UNKNOWN обрабатывается так же, как FALSE. Например, если вы выбираете строки из таблицы, а условие x = NULL в предложении WHERE дает UNKNOWN, то вы не получите никаких строк. Однако есть одно отличие: если выражение NOT(FALSE) возвращает true, то NOT(UNKNOWN) возвращает UNKNOWN. Логические операторы AND и OR также имеют свои свои особенности при обработки состояния неизвестности. Конкретика - в примерах ниже.
В большинстве случаев результат unknown трактуется как FALSE:
select 1 from dual where dummy = null; -- запрос не вернет результатаОтрицание unknown дает unknown:
exec testBool( not(null = null) ); -- UNKNOWN
exec testBool( not(null != null) ); -- UNKNOWN
exec testBool( not(null = 'a') ); -- UNKNOWN
exec testBool( not(null != 'a') ); -- UNKNOWNОператор OR:
exec testBool( null or true ); -- TRUE <- !!!!!
exec testBool( null or false ); -- UNKNOWN
exec testBool( null or null ); -- UNKNOWNОператор AND:
exec testBool( null and true ); -- UNKNOWN
exec testBool( null and false ); -- FALSE <- !!!!!
exec testBool( null and null ); -- UNKNOWNОператоры IN и NOT IN
Давайте начнем с нескольких предварительных мероприятий. Для тестов создадим таблицу T с одним числовым столбцом A и четырьмя строками: 1, 2, 3 и NULL.
create table t as
select column_value a from table(sys.odcinumberlist(1,2,3,null));Включите трассировку запросов (для этого у вас должна быть роль PLUSTRACE).
В листинге трассировки оставлена только фильтрующая часть, чтобы показать, во что разворачиваются условия, указанные в запросе.
set autotrace onПрелюдия закончена. Теперь давайте поработаем с операторами. Попробуем выбрать все записи, которые включены в набор (1, 2, NULL):
select * from t where a in ( 1, 2, null ); -- будет возвращено [1, 2]
-- Predicate Information:
-- filter("A"=1 OR "A"=2 OR "A"=TO_NUMBER(NULL))Как можно увидеть, строка с NULL не была выбрана. Это связано с тем, что оценка предиката "A"=TO_NUMBER(NULL) вернула статус UNKNOWN. Для того, чтобы включить значения NULL в результаты запроса, вам нужно задать его явно:
select * from t where a in ( 1, 2 ) or a is null; -- вернется [1, 2, NULL]
-- Predicate Information:
-- filter("A" IS NULL OR "A"=1 OR "A"=2)Теперь попробуем с NOT IN:
select * from t where a not in ( 1, 2, null ); -- ничего не выбрано
-- Predicate Information:
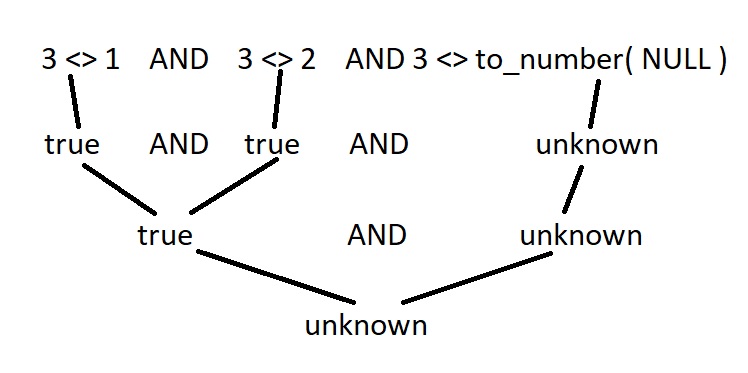
-- filter("A"<>1 AND "A"<>2 AND "A"<>TO_NUMBER(NULL))Вообще ни одного результата! Давайте посмотрим, почему тройка не была включена в результаты запроса. Вручную вычислим фильтр, применяемый СУБД для случая A = 3:
В силу особенностей трехзначной логики, NOT IN вообще не дружит с NULL: как только NULL встречается в условиях отбора, не ждите никаких данных.
NULL и пустая строка
Здесь Oracle отходит от стандарта ANSO SQL и заявляет об эквивалентности NULL и пустой строки. Это, возможно, наиболее спорный момент, который время от времени поднимает многостраничные дискуссии с переходом на личности и другие непременные атрибуты жестких споров. Судя по документации, сам Oracle был бы не против изменить эту ситуацию (говоря, что хотя сейчас пустая строка трактуется как NULL, это может измениться в будущих релизах), но в настоящее время для этой СУБД написано такое огромное количество кода, что принять изменение поведения системы вряд ли реально. Более того, они начали говорить об этой по меньшей мере, начиная с седьмой версии (1992-1996), а сейчас на подходе двенадцатая.
NULL и пустая строка эквивалентны:
exec testBool( '' is null ); -- TRUEЕсли последовать завету классика и посмотреть в корень, то причина эквивалентности пустой строки и NULL может быть обнаружена в формате хранения varchar и NULL в блоках данных. Oracle хранит строки таблицы в структуре, состоящей из заголовка, за которым следуют столбцы данных. Каждый столбец представлен двумя полями: длиной данных в столбце (1 или 3 байта) и самими данными. Если varchar2 имеет нулевую длину, то в поле данных нечего записывать, это не занимает ни одного байта, и в поле длины записывается специальное значение 0xFF, означающее отсутствие данных. NULL представлен точно так же: поле данных отсутствует, а в поле длины записывается 0xFF. Разработчики Oracle могли бы, конечно, разделить эти два состояния, но так было у них с давних времен.
Конкретно для меня эквивалентность пустой строки и NULL кажется довольно естественным и логичным. Само имя "пустая строка" подразумевает отсутствие смысла, пустоту, дырку от бублика. NULL в целом означает то же самое. Но тут имеется неприятное последствие: Если мы можем с определенностью сказать, что пустая строка имеет нулевую длину, то о длине NULL так определенно не скажешь. Следовательно, выражение length('') будет возвращать NULL, а не нуль, как вы очевидно ожидали. Другая проблема: вы не можете сравнивать с пустой строкой. Выражение val = '' вернет состояние UNKNOWN, т.к. фактически это эквивалентно val = NULL.
Длина пустой строки является неопределенной:
select length('') from dual; -- NULLНевозможно сравнение с пустой строкой:
exec test_bool( 'a' != '' ); -- UNKNOWNКритики подхода Oracle утверждают, что пустая строка не обязательно означает "неизвестно". Например, менеджер по продажам заполняет карточку клиента. Он мог указать свой контактный номер (555-123456), мог указать, что он неизвестен (NULL), или мог указать, что контактного номера нет (пустая строка). При методе хранения пустых строк в Oracle будет проблематичным применить последний вариант. С точки зрения здравого смысла аргумент справедлив, но я всегда спрашиваю и не получаю четкого ответа: как менеджер будет вводить пустую строку в поле "phone", и как он будет в последующем отличать ее от NULL? Конечно, есть варианты, но все же...
На самом деле, если мы говорим о PL/SQL, то где-то глубоко внутри ядра пустая строка и NULL различаются. Это можно увидеть, поскольку ассоциативные коллекции позволяют вам сохранить элемент с индексом '' (пустая строка), но не позволяет сохранить элемент с индексом NULL:
declare
procedure empty_or_null( p_val varchar2 )
is
type tt is table of varchar2(1) index by varchar2(10);
t tt;
begin
if p_val is not null then
dbms_output.put_line('not null');
else
-- пытаемся создать элемент с индексом p_val
t(p_val) := 'x';
-- получилось!
dbms_output.put_line('empty string');
end if;
exception
-- нет возможности создать элемент с индексом p_val
when others then dbms_output.put_line('NULL');
end;
begin
empty_or_null( 'qwe' ); -- не NULL
empty_or_null( '' ); -- пустая строка
empty_or_null( NULL ); -- NULL
end;Для того, чтобы избежать проблем, лучше уяснить для себя правило из документации: пустая строка и NULL неотличимы в Oracle.
Математические операции с NULL
select decode( null + 10, null, 'UNKNOWN', 'KNOWN') a from dual; -- UNKNOWN
select decode( null * 10, null, 'UNKNOWN', 'KNOWN') a from dual; -- UNKNOWN
select decode( abs(null), null, 'UNKNOWN', 'KNOWN') a from dual; -- UNKNOWN
select decode( sign(null), null, 'UNKNOWN', 'KNOWN') a from dual; -- UNKNOWNПоведение конкатенации отличается: вы можете добавить NULL к строке, и это не изменит ее. Это политика двойных стандартов.
select null || 'AA' || null || 'BB' || null from dual; -- AABBNULL и агрегатные функции
Почти все агрегатные функции, за исключением COUNT (и даже это не всегда), игнорируют NULL-значения при вычислениях. Если этого не делать, то первое же попавшееся значение NULL дало бы результату функции значение unknown. Возьмем для примера функцию SUM, с помощью которой необходимо просуммировать ряд (1, 3, null, 2). Если учитывать пустые значения, то мы должны получить следующую последовательность действий:
1 + 3 = 4; 4 + null = null; null + 2 = null.Вас вряд ли бы удовлетворило такое вычисление агрегатов.
Эта таблица с данными будет неоднократно использоваться ниже:
create table agg( id int, n int );
insert into agg values( 1, 1 );
insert into agg values( 2, 3 );
insert into agg values( 3, null );
insert into agg values( 4, 2 );
commit;Пустые значения игнорируются агрегатами:
select sum(n) from agg; -- 6Функция COUNT подсчитывает строки; если используется COUNT(*) или COUNT(константа), NULL-значения будут учитываться. Однако если используется COUNT(выражение), то значения NULL будут игнорироваться.
С константой:
select count(*) from agg; -- 4
select count(1+1) from agg; -- 4
select count(user) from agg; -- 4С выражением:
select count(n) from agg; -- 3
select count(id) from agg; -- 4
select count(abs(n)) from agg; -- 3также следует быть осторожным с функцией AVG. Поскольку она игнорирует значения NULL, результатом для столбца N будет (1+3+2)/3, а не (1+3+2)/4. Возможно вам не подходит такое вычисление среднего значения. Для решения проблемы есть стандартное решение - использование функции NVL:
select avg(n) from agg; -- (1 + 3 + 2) / 3 = 2
select avg(nvl(n,0)) from agg; -- (1 + 3 + 0 + 2) / 4 = 1.5Агрегатные функции возвращают UNKNOWN, если они применяются к пустому набору данных или если набор данных содержит только значения NULL. Исключение составляют функции REGR_COUNT и COUNT(выражение), предназначенные для вычисления числа строк. Они вернут нуль в перечисленных выше случаях.
Набор данных, состояший только из NULL:
select sum(n) from agg where n is null; -- UNKNOWN
select avg(n) from agg where n is null; -- UNKNOWN
select regr_count(n,n) from agg where n is null; -- 0
select count(n) from agg where n is null; -- 0Пустой набор данных:
select sum(n) from agg where 1 = 0; -- UNKNOWN
select avg(n) from agg where 1 = 0; -- UNKNOWN
select regr_count(n,n) from agg where 1 = 0; -- 0
select count(n) from agg where 1 = 0; -- 0NULL в индексах
При создании индекса Oracle включает записи в индексные структуры для всех строк, содержащих значения NULL в индексируемом столбце. Такие записи называются NULL-записями. Это позволяет вам быстро идентифицировать строки, где соответствующий столбец содержит NULL, что может быть полезно при выполнении запросов с NULL и не-NULL условиями.
- Использование NULL-значений в обычных индексах: Обычные индексы включают ссылки на строки таблицы, указывая значения индексируемого столбца и соответствующие значения ROWID этих строк. Для строк с NULL-значениями индекс хранит специальный маркер NULL для обозначения наличия NULL в индексируемом столбце. Это позволяет Oracle быстро находить строки с NULL в индексируемом столбце.
- Использование значений NULL в составных индексах: В составных индексах, которые индексируют несколько столбцов, каждый столбец имеет свою собственную индексную структуру. Таким образом, для составных индексов, содержащих столбцы с NULL, токен NULL будет присутствовать для каждого столбца, содержащего значения NULL.
- Функциональные индексы и NULL: Функциональные индексы строятся на основе выражений или функций на столбцах таблицы. Если функция допускает аргументы NULL, то индекс будет включать записи для аргументов функции NULL. Это может быть полезно при оптимизации запросов, которые используют допускающие NULL-значения функции.
Плохая практика
- Индексирование столбцов с низким кардинальным числом значений NULL: Создание индексов на столбцах, в которых большинством значений является NULL, может привести к неоптимальному использованию индекса и плохой производительности запросов. Это обусловлено тем, что индексы с низкой кардинальностью NULL-значений будут занимать много места в базе данных, и запросы с такими индексами могут оказаться медленней, чем полное сканирование таблицы.
- Индексирование неселективных столбцов с NULL: Неселективные столбцы - это столюцы, которые имеют незначительное число уникальных значений или много дублирующих значений NULL. Создание индексов на таких столбцах может оказаться непрактичным, поскольку такие индексы не обеспечивают значительного улучшения производительности запросов и требуют больше ресурсов для обслуживания.
- Использование индексов с NULL при операторах IS NOT NULL: Если запрос содержит условия с оператором IS NOT NULL, то NULL-индексы не будут использоваться оптимизатором запросов. Т.к. использование NULL-индексов в таких запросах будет бесполезной тратой ресурсов на создание и обслуживание ненужных индексов.
- Индексирование больших текстовых столбцов с NULL-значениями: Создание индексов на больших текстовых столбцах, которые могут содержать NULL-значения, может быть невыгодным по причине большого количества данных, которые должны храниться в индексе. Индексирование таких столбцов может значительно увеличить размер индекса и замедлить выполнение запросов.
- Чрезмерное использование функциональных индексов с NULL: Функциональные индексы могут быть полезны для оптимизации запросов с функциями, которые допускают аргументы NULL. Однако широкое использование функциональных индексов с NULL может привести к нежелательному размеру индексов и падению производительности.
- Нерелевантные и неиспользуемые индексы с NULL: Устаревшие и неиспользуемые индексы с NULL-значениями сохраняются в базе данных, занимают пространство и требуют обновления при изменении данных. Такие индексы необходимо регулярно отслеживать и удалять для уменьшения нагрузки на систему и оптимизации производительности.
Важно помнить, что использование NULL в индексах может быть полезным, но не всегда. При создании индексов с NULL следует уделать внимание кардинальности NULL-значений в столбцах и их фактическому использованию в запросах. Это поможет избежать ненужных индексов и улучшить производительность базы данных.
Хорошая практика
- Индексирование столбцов с высокой кардинальностью NULL-значений: Создание индексов на столбцах с высоким значением кардинальности NULL может быть выгодным, т.к. индексы позволят вам быстро идентифицировать строки с NULL-значениями. Это особенно полезно, когда запросы часто используют условия на NULL и не-NULL значения в столбце.
- Индексирование столбцов обычно используемых в запросах: Создание индексов на столбцах, которые часто используются в запросах, может значительно улучшить производительность запросов. Индексы могут помочь ускорить извлечение данных и снизить время выполнения запроса.
- Использование функциональных индексов с NULL: Функциональные индексы могут быть полезны для оптимизации запросов с функциями, которые допускают аргументы NULL. Такие индексы могут улучшить производительность запросов, которые используют функции с аргументами NULL.
- Использование индексов с NULL в комбимнациии с IS NULL: Индексы с NULL могут быть очень полезны при использовании с оператором IS NULL для нахождения строк с NULL-значениями. Такие индексы позволят вам быстро находить все строки с NULL в соответствующих столбцах.
Анализ производительности индексов, использующих NULL
При создании индлексов с NULL рекомендуется проанализировать производительность запросов и сравнить ее с производительностью без индексов. Это поможет вам определить индексы с NULL, которые действительно улучшают производительность и оправданы в вашей конкретной ситуации.
- Периодическое обслуживание индексов: Как и обычные индексы, NULL-индексы требуют периодического обслуживания. Регулярное обновление статистики индексов поможет оптимизатору запросов корректно оценивать планы выполнения запросов и избежать ненужных операций.
- Удаление неиспользуемых NULL-индексов: Неиспользуемые NULL-индексы должны регулярно отслеживанися и удаляться для уменьшения нагрузки на систему и отпимизации производительности базы данных.
- Контроль обновлений и вставок: При использовании NULL-индексов необходимо контролировать операции обновления и вставки. NULL-индексы могут влиять на производительность таких операций, поэтому важно учитывать их при проектировании и оптимизации запросов.
Следование этой практике позволит эффективно использовать NULL-значения в индексах Oracle, улучшить производительность запросов и уменьшить воздействие на систему. Широкое использование NULL-индексов поможет вам получить максимум от использования индексов и повысит эффективность базы данных.
Ссылки по теме
1. Трехзначная логика и предложение Where
2. Столбцы, допускающие NULL-значения, и производительность
3. Правильный способ проверки на NULL в запросах SQL Server
4. Соединение таблиц в SQL Server, когда столбцы включают NULL-значения
5. Агрегатные функции
6. Агрегатная функция от агрегатной функции
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой