
Функциональность или производительность?
Пересказ статьи Grant Fritchey. FUNCTION VS. PERFORMANCE
Недавно я просматривал DBA.StackExchange, когда увидел довольно простой вопрос, на который я решил ответить. Я вышел, установил тестовую базу данных, создал некоторые таблицы для тестирования и быстро написал запрос для ответа на вопрос. Пока я его форматировал для публикации, увидел, что был уже дан другой ответ.
Да, идентичный моему. Почти строка в строку.
Ну, почти.
Я понимаю, что буду писать статью в блог.
Установка
Автор поста имел две таблицы, которые, откровенно говоря, были плохо спроектированы. Однако они содержали достаточно "связанных" данных, хотя и нереляционно. Вот код:
CREATE DATABASE Testing;
GO
USE Testing;
GO
CREATE TABLE Table_A
(
ID INT IDENTITY(1, 1),
Score INT
);
CREATE TABLE Table_B
(
FromPoint INT,
ToPoint INT,
RankDesc VARCHAR(50)
);
INSERT dbo.Table_A
(
Score
)
VALUES
(67),
(569),
(123);
INSERT dbo.Table_B
(
FromPoint,
ToPoint,
RankDesc
)
VALUES
( 1, -- FromPoint - int
99, -- ToPoint - int
'Top 100' -- RankDesc - varchar(50)
),
( 100, -- FromPoint - int
499, -- ToPoint - int
'Top 500' -- RankDesc - varchar(50)
),
( 500, -- FromPoint - int
1000, -- ToPoint - int
'Top 1000' -- RankDesc - varchar(50)
);Итак, требовался запрос, который связал бы таблицы и распределил значения из таблицы A по категориям ОТ (FromPoint ) и ДО (ToPoint ) в Table_B, чтобы найти ранг. Я написал такой запрос:
SELECT ta.ID,
tb.RankDesc
FROM dbo.Table_A AS ta
JOIN dbo.Table_B AS tb
ON ta.Score
BETWEEN tb.FromPoint AND tb.ToPoint;Полностью функциональный. Однако я уже слышу как вопят настроечные мелочи. Давайте поговорим об этом.
Функция против производительности
Пожалуйста, давайте уйдем от преждевременной дискуссии относительно производительности и просто скажем, что иногда мы можем определить проблемные вещи и исправить их до того, как они станут проблемами, конечно, ничему не вредя.
Вот существующий план выполнения:
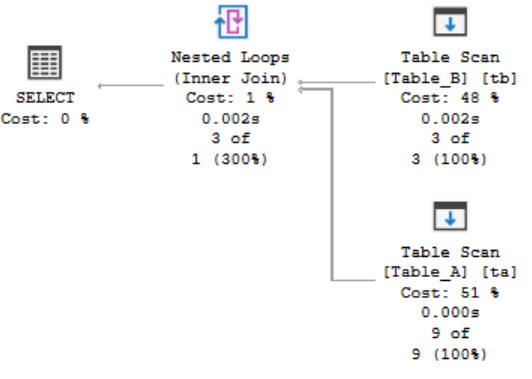
Ничего действительно шокирующего или удивительного нет в основной форме плана. Нет ничего в представленной структуре, что поддерживало бы этот запрос, поэтому мы видим сканирование таблиц (и я не создавал никакого первичного ключа или кластеризованного индекса; итак, это все, что есть). Единственный интересный момент - это Nested Loops Predicate:
[Testing].[dbo].[Table_A].[Score] as [ta].[Score]>=[Testing].[dbo].[Table_B].[FromPoint] as [tb].[FromPoint]
AND [Testing].[dbo].[Table_A].[Score] as [ta].[Score]<=[Testing].[dbo].[Table_B].[ToPoint] as [tb].[ToPoint]Даже, хотя я написал “BETWEEN”, оптимизатор решил изменить его на >= and <=. На самом деле то же самое, но если вы хотите хоть немного сократить работу оптимизатора, то могли бы переписать соединение следующим образом:
SELECT ta.ID,
tb.RankDesc
FROM dbo.Table_A AS ta
JOIN dbo.Table_B AS tb
ON ta.Score >= tb.FromPoint
AND ta.Score <= tb.ToPoint;На тысячах выполнений это помогло бы сбросить миллисекунду. Нет, нам нужны индексы.
Индексы
Как и в случае с настройкой запросов, правильная структура имеет значение. Вероятно, мне необходимо добавить кластеризованный индекс для этих таблиц, чтобы действительно сделать их правильными. Тем не менее, мы просто собираемся попробовать пару индексов.
Но сначала я собираюсь загрузить больше данных, чтобы у нас появилось множество страниц, и оптимизатор обнаружил, что созданные мной индексы могут помочь. Я собираюсь схолтурить и использовать Генератор Данных (эй, я работаю в Redgate и ленюсь, когда это возможно). С множеством данных план выполнения меняется:
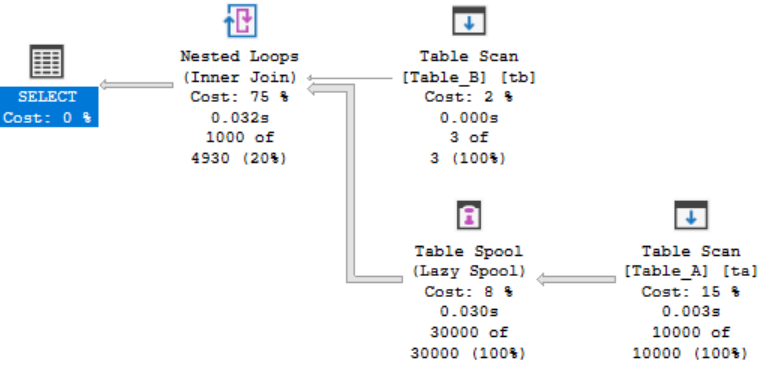
Это сделано, теперь попробуем такой индекс:
CREATE INDEX ScoreTableA ON dbo.Table_A (Score) INCLUDE (ID);Я намеренно сделал его покрывающим. Вот результирующий план выполнения:
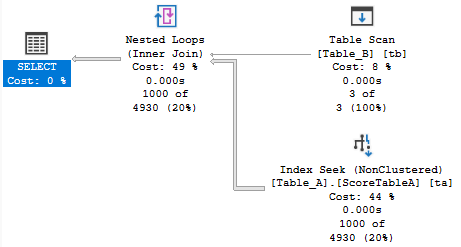
Ну, это определенно выглядит лучше, но план выполнения НЕ ЯВЛЯЕТСЯ мерой производительности. Вот метрики производительности до и после добавления этого индекса:
До:
Reads: 20312
Duration: 27.153ms (примечание: я тестировал c BETWEEN, и он был в среднем на 100 мкс медленнее за 100 выполнений, вот так)
После:
Reads: 44
Duration: 3.76msЭто довольно показательно. Я думаю, что могу уверенно сказать, что индекс помог. На 88% быстрее и на 99,998% меньше чтений. Мне представляется, что это не пустяк.
Стоит ли теперь беспокоиться по поводу сканирования таблицы Table_B? Именно в этой ситуации для трех строк и запроса без предложения WHERE я бы сказал нет. Однако тестирование - ваш друг. Давайте создадим этот индекс:
CREATE INDEX FromAndTo
ON dbo.Table_B (
FromPoint,
ToPoint
)
INCLUDE (RankDesc);Это меняет план выполнения:
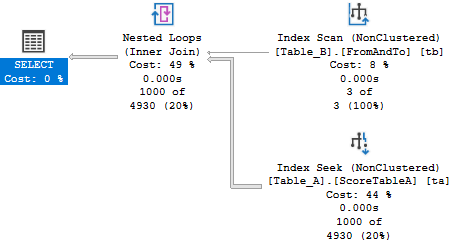
Производительность теперь выглядит так:
Reads: 40
Duration: 2.057msЭто немного помогает. Не сокрушительно, но все же. Честно говоря, я бы назвал этот показатель преждевременной оптимизацией. Фактически это может оказаться излишней оптимизацией в зависимости от того, насколько часто выполняются вызовы, изменяются со временем данные и т.п. На что еще следует обратить внимание для обеих таблиц, так это на возможность выполнения для них кластеризации (имея в виду то, что индекс на таблице Table_A может не быть уникальным), но я оставлю вам тестирование этого случая.
Заключение
Изначально меня больше интересовало создание функционального кода. Но затем, когда я не смог запостить ответ, поскольку кто-то опередил меня, я решил что-то с этим сделать. Почему не оптимизировать?
Вся настройка запросов не сводится лишь к добавлению индексов. Однако, когда вы можете взглянуть на фрагмент кода в сочетании со структурой и сразу заметить, что без индекса он будет работать плохо, то добавление индекса имеет смысл. Когда дело доходит до выбора между функциональностью и производительностью, то я бы сказал, что тут нет выбора, пока не будет достигнут минимальный уровень производительности. Мы перешли от 20312 чтений к 44, а затем к 40. Это не просто преждевременная оптимизация. Это верно функционально.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой